最終更新
AWS・Azure・GCP について、最新の障害情報を取得する方法を説明します。
目次
AWS・Azure・GCP 公式障害情報
AWS・Azure・GCP の障害情報やステータスを取得する方法をまとめます。
AWS の障害情報
Service Health Dashboard にあります。
下記のように、現在の情報 (Recent Events) と、過去の情報 (Remaining Services) に分かれています。
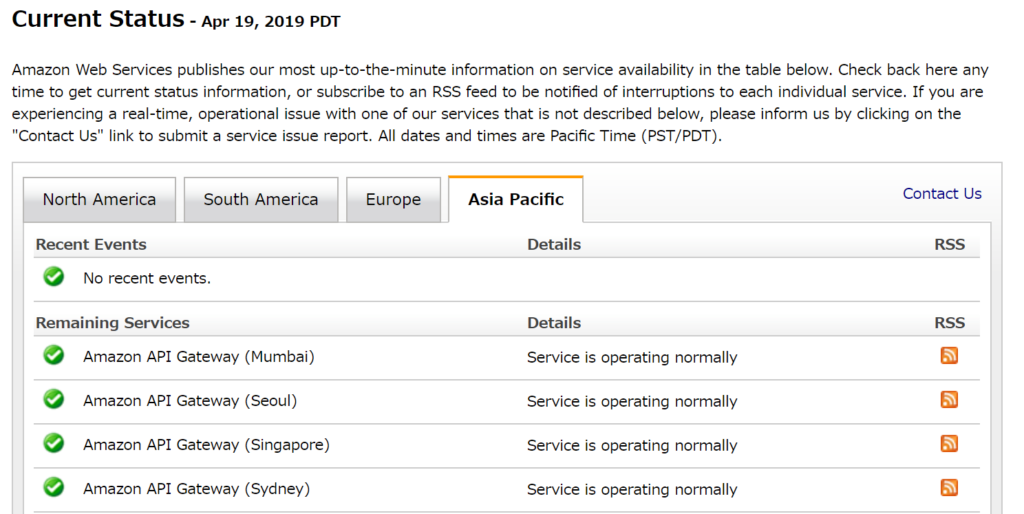
右側の「RSS」をクリックすると、過去の障害履歴が載っています。ただ、いつまでの情報が載っているかがよくわかりません。2012年の情報があるものもあれば、かなり以前からあるサービスなのに 2019年の情報しかないものもあります。最大15件のようにも見えるのですが、判断がつきませんでした。
また、画面一番下から、過去の大規模障害に対する原因と対策レポートに飛ぶことができます。

RSS フィードが数百個あるので調べるのも大変ですが、
https://status.aws.amazon.com/rss/all.rss という全部入りの RSS フィードもあります。ただし直近 15個のみです。また、なぜか AWS サイトからリンクが無いように見えます。以前はリンクされていたのか、あるいは誰かが URL を推測して見つけたのかは不明です。
Azure の障害情報
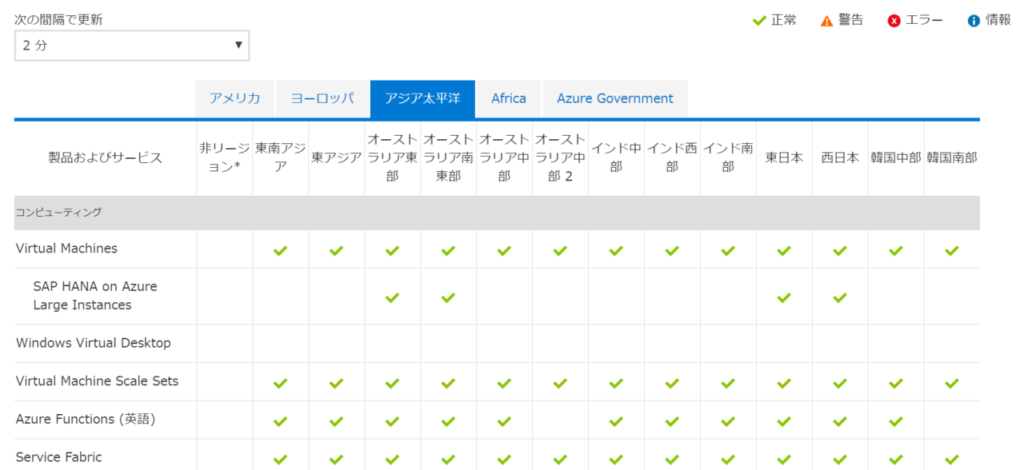
Azure の状態 にあります。リージョン別に稼働状況がわかれています。
また、画面右上にある「状態の履歴」というリンクから、下記のような詳細履歴に飛ぶことができます。 ただし直近90日分しか閲覧できないのが大変残念です。
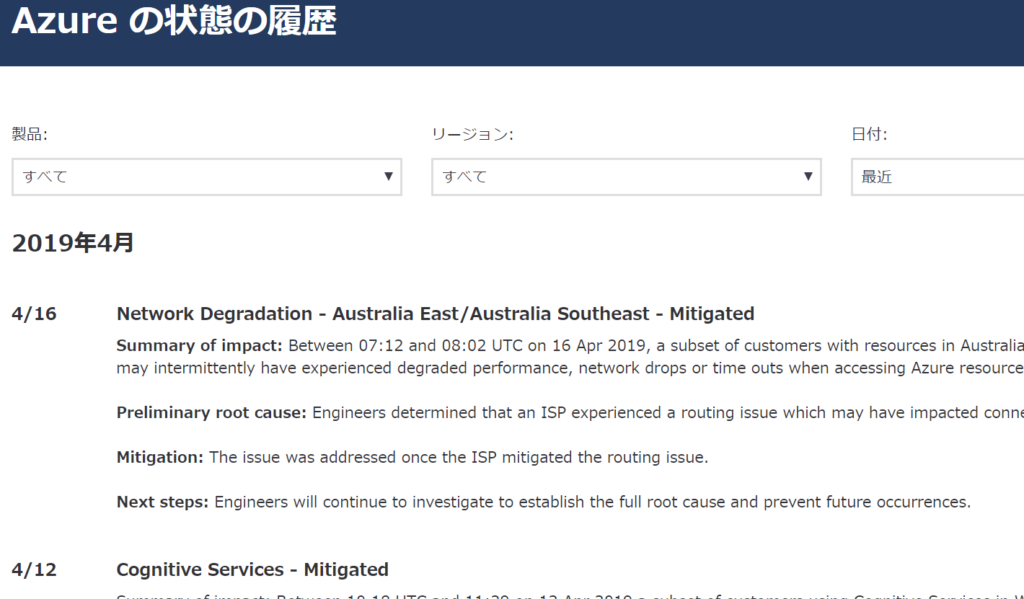
大きめの障害の場合、下記のように RCA (原因調査報告書) の体裁になっています。サマリ・回避策や、再発防止のために今後マイクロソフトが行うタスク (完了か進行中かがわかる) が載っています。

RSSフィードは下記からたどれます。リージョン別の RSS などはなく、全部入りの 1種類しかないようです。
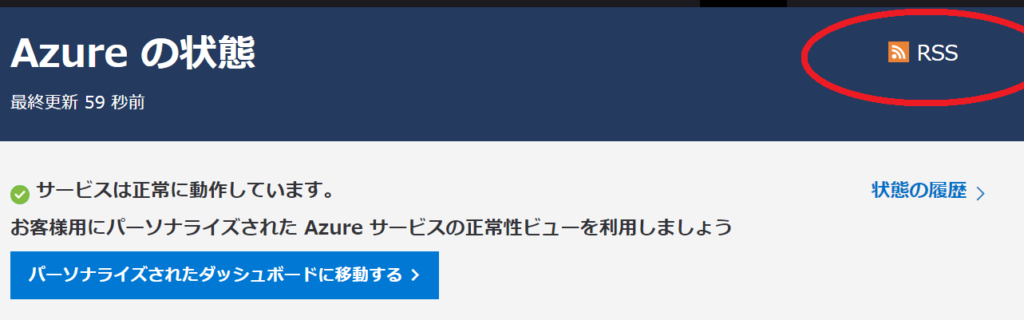
地味なところですが、下記のようにいつの情報なのかがわかるのはいいですね。どうやら毎分更新されているようです (ただし26秒前に取得した情報だからと言って、26秒前に全サービスの障害情報を調べた結果かというと違うでしょうけれども)。

GCP の障害情報
Google Cloud Status Dashboard にあります。
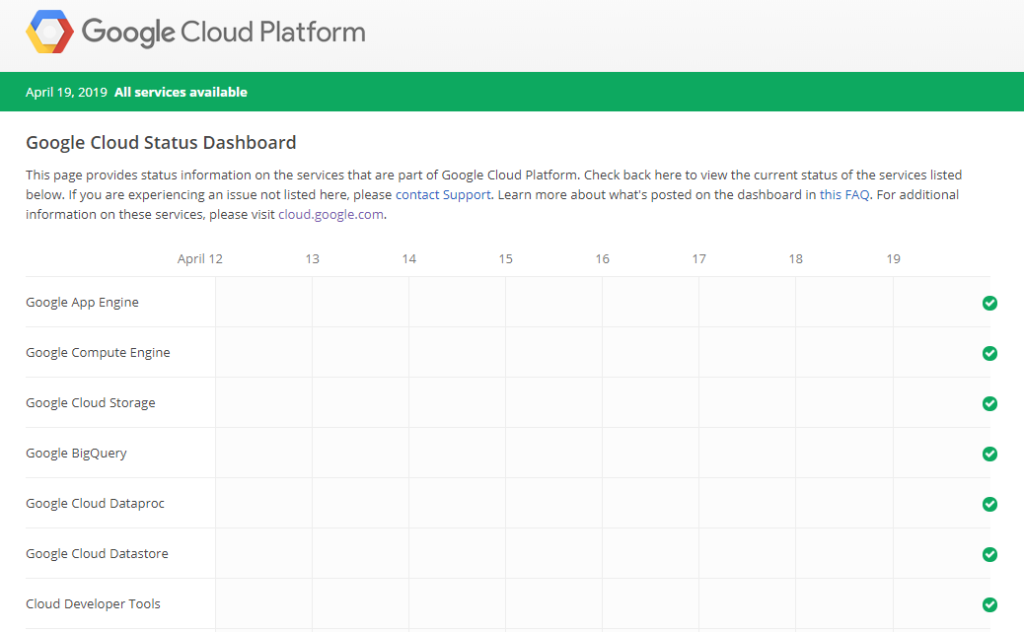
画面下の「View Summary and History」をクリックすると、下記のようなサービス別の障害一覧画面に遷移します。直近1年間分しか記載されていません。
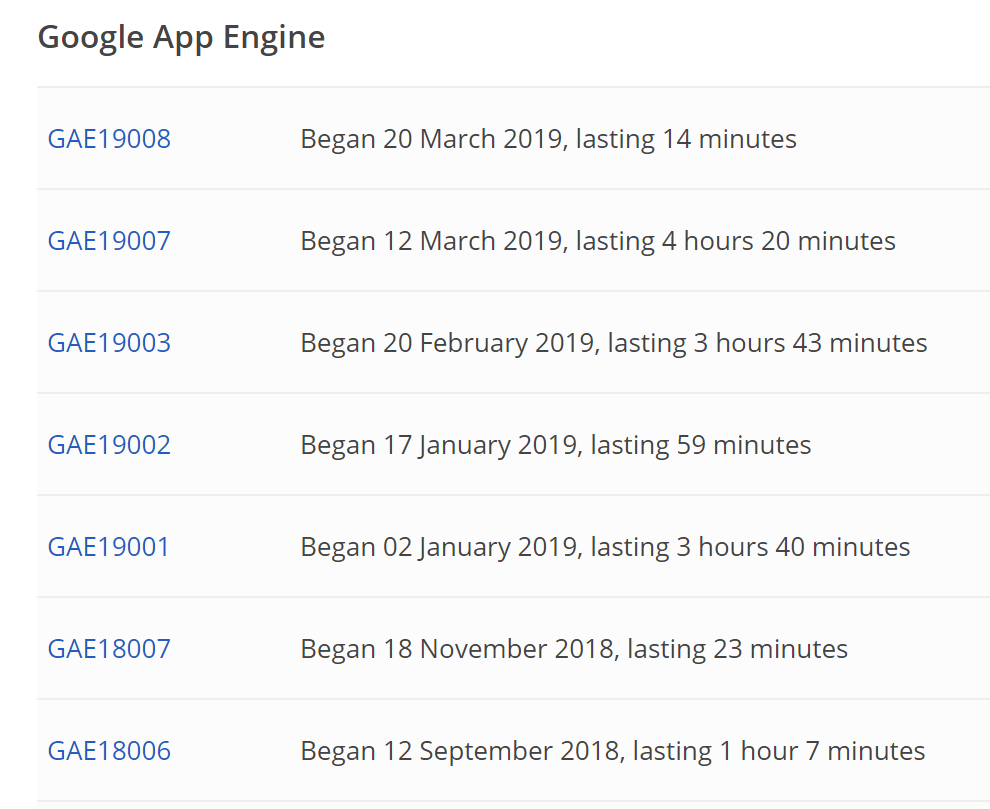
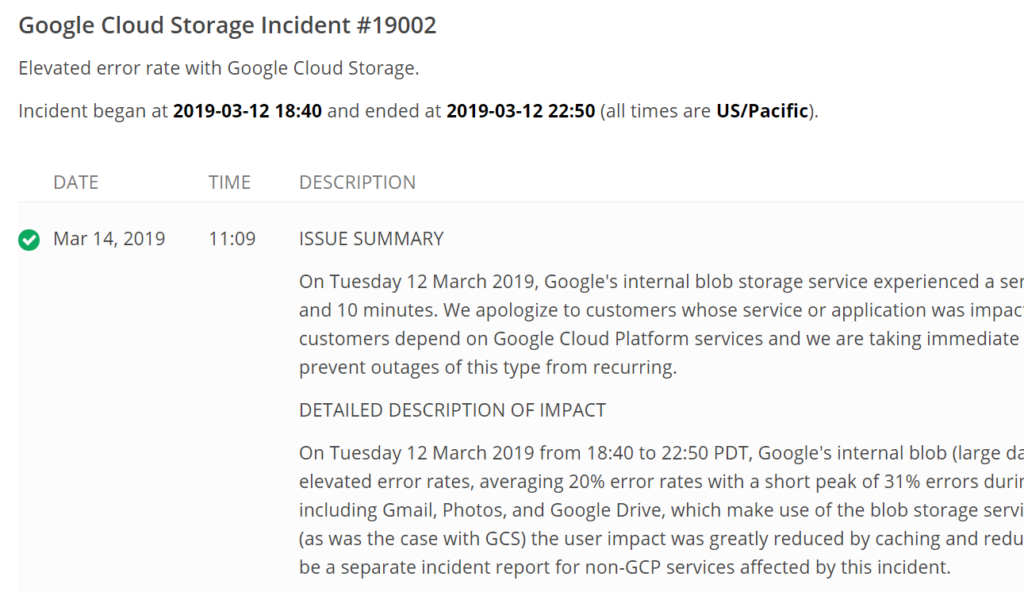
影響の大きい障害の場合、下記のようにサマリ・影響詳細・原因・今後の対策が記載されています。
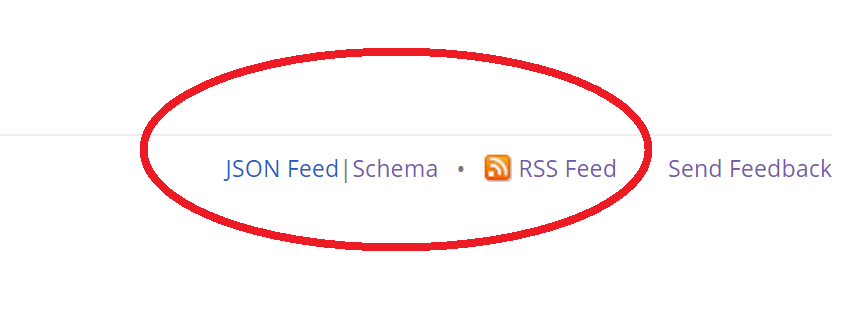
RSS フィードは画面右下からたどれます。直近20件のみのようです。
公式ダッシュボードは信用できるか
これらの、各ベンダが公表する公式ダッシュボードは信用できるか。 当ページ管理人の考えは、「信用できない。あくまでひとつの情報源として扱うべし」です。
理由は、「小規模障害は載らない」「単なる機能バグは載らない」「反映が遅い」ため。
小規模障害は載らない
「小規模障害は載らない」について。 クラウドサービス側の問題であっても、一定以上のユーザに影響が出ることが確認できないと、 ダッシュボードには載りません。少なくとも GCP はそう明言しています。そもそもハード故障は必ず起こるものであり、しかも何十万台・何百万台もあるサーバの 1台や、 あるいは 1ラックが落ちたとしてダッシュボードに載せるのは確かに現実的ではありません。しかしながら、どこまでが小規模障害なのかはわかりません。
これは推測ですが、結局のところダッシュボードに記載するかどうかは人が判断しているのだろうと思います。
クラウドサービス利用者としては、問題の切り分けや関係者への報告をするために、自動的に正常か否かのステータスを出してほしいだけなのに、今はそうなっていないと思われます。
単なる機能バグは載らない
「単なる機能バグは載らない」について。 ダッシュボードに載るのは、ネットワーク障害・広範囲なハードウェア障害ですが、 機能バグは基本的には載りません。 クラウドサービスは機能追加・バグ修正のためのリリースが日々行われています。 さきほどまで動いていたあなたのシステムがいきなり動かなくなったのは、こっそり行われたリリースにて バグが混入されたからかもしれませんが、仮にそうであってもダッシュボードには載りません。 なお、いつ、どのようなリリースが行われるかの事前告知も事後告知もありません。
反映が遅い
「反映が遅い」について。 上記のように、人が判断しているため (推測です)、必然的に反映が遅くなります。 Azure で発生した東日本リージョン全体の障害で 1時間近くダッシュボードが更新されなかったことがありました。 また、笑い話ではありますが、AWS の S3 障害の際は、「ダッシュボード機能が S3 に依存していたため、最新情報を表示できない」というトラブルもありました。
非公式の調査方法
公式ダッシュボードが信用できないなら非公式なものに頼るしかありません。まず当ページ管理人がおすすめするのは Twitter です。
こういうときは Twitter で、「AWS」「Azure」「GCP」と検索するのが一番よいと思っています。 クラウドが原因となる障害は発生していた場合、誰かしらがつぶやいています。 誰もつぶやいていないなら、それはあなたのアカウントだけに発生している問題か、不人気サービスで誰も使っていないかです。
障害通知用の非公式 Twitter アカウント
SNS で速報が欲しい場合や、時系列で見たい場合、松浦隼人氏 (doublemarket) が、上記サイトの RSS フィードを自動収集して ツイートするアカウントを提供されています。
詳細は作者の記事 「AWS, GCP, Azureの障害情報の提供方法とTwitterボット」 を参照してください。
また、ダッシュボードの情報を Slack 連携・Chatwork 連携する方法なども、ググればすぐに見つかりますので、似たような機能を自作することも可能でしょう。
GCP のダメな障害開示の例
GCP に Stackdriver Logging という Web 上でログを表示できるサービスがあるのですが、ある日このサービスにてログ表示の遅延が発生しました。実際には出力されているログが 30分経っても 1時間経っても Web 画面には出てこなかったのです。
このとき、Stackdriver の行はグリーン「✓」のままでした。

しかしながら画面の一番下までスクロールすると、しれっと「ログ表示遅れに対応中」と書いてあります。
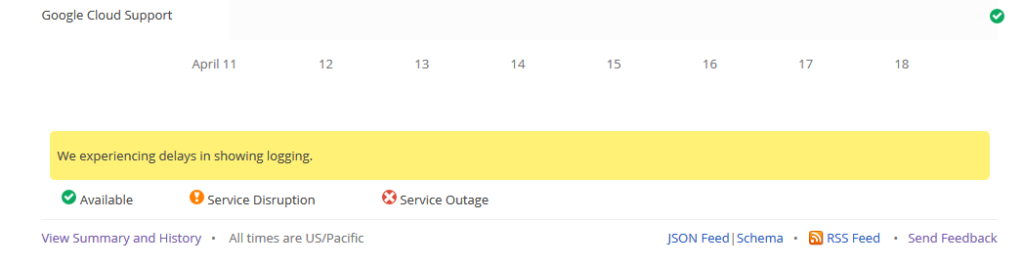
その後、一番下の表記が下記に変わりました。「影響を受けている人が少ないため、個別にサポートに連絡せよ。このダッシュボードでは今後本件について更新しない」とのこと。

さらに30分後、想定よりも影響範囲が大きいことが発覚したのか、正式なインシデントとして「×」マークが付きました。

「×」マークをクリックするとインシデント詳細画面に遷移するようになりました。
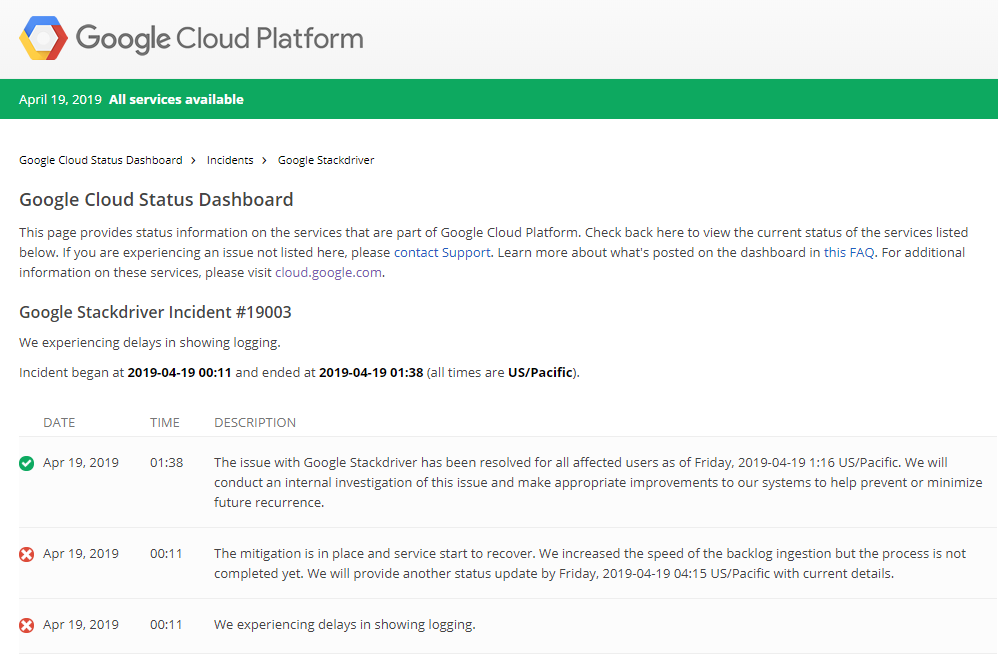
インシデントとなるまでに障害発生から 4時間半でした。ログという裏側のサービスとはいえ、4時間半も経たないと正式な障害として対応できず、RSS フィードなどで読んでいる人は 4時間半気づけなかったということです。「サービスを絶対に落とすな」と言いたいのではなく、「障害が発生しているのであれば迅速にわかりやすく教えてほしい」だけです。
「GCP は利用者のことは考えず、技術だけが好きなエンジニアたちがが好き勝手にやっているクラウドサービスであるため、ビジネス用途には向かない」という人もいます。こんないい加減なことをやっているようでは、反論できませんね。