最終更新
Google Cloud Platform 最強のサービスと言っても過言ではないデータウェアハウスエンジン BigQuery。AWS や Azure を使っていても、データ分析だけは BigQuery で、という話はよく聞きます。このページでは BigQuery に関するよくある質問をまとめました。
- 2020/06/12 BigQueryの権限 についての解説を追加。
- 2020/05/17 更新。
- 2020年4月に beta リリースされた マテリアライズド・ビューの説明 を追加。
- 2020/05/16 更新。BI Engine において、BigQuery ビュー・Data Studio カスタムクエリも高速化対象となったことを追記。
- 2020/01/16 更新。
目次
BigQuery の基礎
BigQuery とは何か?
BigQuery とは、Google が提供するデータベース・データウェアハウスサービスで、Google のクラウドサービス Google Cloud Platform (GCP) の一部です。
BigQuery で何ができる?
データの分析やデータ保管庫として活用するのが一般的です。
データベースなのでおおむねどのようなデータでも格納できますが、BigQuery が得意なデータは、会員情報・売上情報・在庫情報・アクセスログなどです。
特に、何十億・何百億レコードをそこそこ高速に処理できるのが強みです。
競合サービスは?
クラウド界隈の競合サービスは下記です。
- AWS の Redshift
- Azure の Synapse Analytics (旧名 SQL Data Warehouse)
- Oracle の Oracle Autonomous Data Warehouse
- Snowflake 社の Snowflake (AWS 上に構築された DWH)
一般的な RDBMS、Oracle・MySQL・PostgreSQL と比べて何が違うの? メリット・デメリットは?
BigQuery は大規模データに特化したつくりになっています。大量のデータを扱えますが、リアルタイム性には劣ります。また、主キー・CHECK 制約・参照整合性制約など不正データを混入させないという観点の機能が欠けています。
よって、 EC サイトなど、多数の一般利用者が使うシステムのデータベースとしては適していません。EC サイトそのものは Oracle・MySQL・PostgreSQL を使い、その結果を BigQuery に流し込んで、分析・保存するという使い方をおすすめします。
また、BigQuery は管理の手間が少ないというのは大きなメリットです。なにしろ「インスタンスを立てる」「インスタンスサイズは~を選ぶ」という概念すらありません。
BigQuery は高速ってこと?
状況によります。1レコードしかないテーブルから SELECT でデータを取り出す場合、おおよそ 0.2秒程度かかります。これは Oracle・MySQL・PostgreSQL などと比較すると非常に遅いといえるでしょう。
また、Redshift・SQL Data Warehouse などのクラウドサービスでのデータウェアハウスと比べても、遅いです。
しかしながら、BigQuery は大量データに強いという特徴があります。数百万レコード・数千万レコードあたりから BigQuery が有利になり、数億・数十億レコードともなると BigQuery が圧倒的に有利です。
BigQuery は管理の手間が少ない、とはどういうこと?
当ページ管理人が考える BigQuery 管理の楽な点は下記です。
- インスタンスの概念がないので、インスタンスを起動したり停止したりということを考えなくてよい。
- インスタンスの概念がないので、インスタンスサイズ (CPU・メモリ等) を考えなくてよい。
- 容量の上限が事実上ないので、容量監視やディスク追加を考えなくてよい。
- インデックスがなく常にフルスキャンであるため、インデックスについて考えなくてよい。
- 圧縮は自動的に行われるため、圧縮タイプなどを考えなくてよい。
- ソートキーを考えなくてよい。
プロジェクト・データセット・テーブル
データセットとは?
BigQuery では、他の RDBMS と同様にテーブル単位でデータを保持しますが、テーブルは必ずデータセットという箱の中に存在します。
イメージとしては下記のような親子関係になります。
- データセットA
- テーブルX
- テーブルY
- データセットB
- テーブルX
- テーブルZ
なお、「データセットの下にないテーブル」「複数のデータセットの下にあるテーブル」というものは存在しません。
データセットのロケーションとは?
BigQuery におけるロケーションはとても重要です。なぜなら1つのSQLで、ロケーションをまたぐことはできないため。例えば購入テーブルが Tokyo にあり、マスタテーブルが US にある場合、それを1つのSQLで join することはできません。
また、一度テーブルに格納したデータはロケーションの変更ができません。ロケーションをまたがるコピー (bq cp) もできません。データセットをコピーするには? で異なるロケーションのデータセットにコピーするか、一度 GCS に export して GCS で新ロケーションにコピーし、新ロケーションに bq load する必要があります。
ロケーションはどこにするべき?
ロケーションは下記のような選択肢があります。
- マルチリージョン
- US
- EU
- シングルリージョン
- asia-northeast1 (東京)
- asia-northeast2 (大阪)
- asia-east1 (台湾)
- など
ロケーションにより料金が異なります。下記は一例ですが、最安は US・EU です。日本からの利用であれば、基本的には価格が安く回線が太い US をおすすめします。
2019/10 にシングルリージョンのクエリコストが値下げされました。 asia-northeast-1 (東京) はこれまで US・EU の 1.7倍の $8.55/TB であったものが、ぐっと値下げされて US・EU の 1.2倍である $6.00/TB になりました。これまでは東京は高すぎて選択肢に入ってこなかった方もいると思うのですが、1.2倍となると大変悩ましいですね。
| ロケーション | クエリコスト (1TBあたり) | ストレージコスト(1GBあたり) |
| US | $5.00 | $0.020 / $0.010 |
| EU | $5.00 | $0.020 / $0.010 |
| us-west2 (ロサンゼルス) | $6.75 (2019/10 に $10.35 から値下げ) | $0.023 / $0.016 |
| us-east4 (北バージニア) | $5.00 (2019/10 に $6.45 から値下げ) | $0.023 / $0.016 |
| northamerica-northeast1 (モントリオール) | $5.25 (2019/10 に $7.60 から値下げ) | $0.023 / $0.016 |
| asia-northeast-1 (東京) | $6.00 (2019/10 に $8.55 から値下げ) | $0.023 / $0.016 |
| europe-west6 (チューリッヒ) | $7.00 (2019/10 に $9.20 から値下げ) | $0.025 / $0.017 |
データセットをリネーム・コピーするには? ロケーションを変更するには?
2019/9 よりデータセットのコピーができるようになりました (2021/7 現在、ベータ)。
下記のような作業が楽に行えます。
- 同一ロケーションで、 データセットのコピー・バックアップを取得する
- 同一ロケーションで、データセットのリネームをする (コピー後にコピー元データセットを自分で削除)
- 別ロケーションにデータをコピー・移動する。
参考:https://cloud.google.com/bigquery/docs/copying-datasets?en=ja
テーブルとは?
BigQuery のテーブルは、一般的な RDBMS のテーブルと同じです。テーブル名を持ち、複数のカラムを持ち、カラムには文字列型・数値型などのデータ型があります。
データ型・制約
BigQuery のデータ型は?
BigQuery の主なデータ型は下記のとおりです。
| 型名 | 説明 |
| STRING | 文字列 |
| INTEGER/INT64 | 整数 (64bit符号付き) |
| NUMERIC | 固定小数点型 |
| FLOAT/FLOAT64 | 浮動小数点型 |
| TIMESTAMP | 時刻。0001-01-01 00:00:00~9999-12-31 23:59:59.999999 UTC。タイムゾーンあり |
| DATE | 日付。 0001-01-01 ~ 9999-12-31 。タイムゾーンなし。 |
| DATETIME | 日時。0001-01-01 00:00:00 ~ 9999-12-31 23:59:59.999999 。タイムゾーンなし。 |
| BOOLEAN/BOOL | 真偽値 (TRUE または FALSE) |
| GEOGRAPHY | 地理情報 (緯度経度など) |
| BYTES | バイト列 |
| RECORD/STRUCT | 後述 |
CHAR や VARCHAR は?
BigQuery のデータ型には、CHAR や VARCHAR はありません。STRING を使いましょう。
文字列型の長さ制限はありませんが、1レコードの最大サイズは 100MB と決まっていますので、その枠内なら STRING のカラムに 10MB を突っ込んだりしても大丈夫です。
RECORD とは?
RECORD とはデータ型のひとつであり、構造体のようなもので、foo.bar のようにドットでつなぐことで表現できます。下記の JSON 形式のスキーマ型において、col2 が RECORD 型です。
[
{"name": "col1", "type": "STRING", "mode": "NULLABLE"},
{"name": "col2", "type": "RECORD", "mode": "NULLABLE", "fields": [
{"name": "subcol1", "type": "STRING", "mode": "NULLABLE"},
{"name": "subcol2", "type": "STRING", "mode": "NULLABLE"}
]}
}SQLは下記になります。
-- 全カラムを select
SELECT * FROM mytable
-- col2 を select (subcol1・subscol2 を含む)
SELECT col2 FROM mytable
-- col2.subcol1 のみ select
SELECT col2.subcol1 FROM mytable
-- col2 の subcol1 と subcol2 を select
SELECT col2.subcol1, col2.subcol2 FROM mytable
RECORD 型の使い所・メリットは?
- 例えば売上レコードに購入した店舗情報を含める際、shop と shop.geo をそれぞれ RECORD とし、下記のようにする。
- shop.shop_id (店舗コード)
- shop.shop_name (店舗名)
- shop.geo.prefecture_name (都道府県名)
- shop.geo.city_name (市区町村名)
- shop.geo.latitude (緯度)
- shop.geo.longitude (経度)
- タイミングで分ける。例えば IoT 機器が送信したデータと、中継サーバのデータと、受信時のデータを分けるなど。
- sourceinfo (IoT 機器の送信データ)
- relayinfo (中継サーバの付加データ)
- receiveinfo (受信時のデータ)
- JSON 文字列をそのままマッピングする
- {“foo”: {“bar”: “hoge”, “baz”: [“data1”, “data2”]}} といった JSON データをマッピングする際、下記のようにする。
- foo RECORD
- bar STRING
- baz STRING REPEATED
- foo RECORD
- {“foo”: {“bar”: “hoge”, “baz”: [“data1”, “data2”]}} といった JSON データをマッピングする際、下記のようにする。
- レイヤ分けをする。例えば
- commnication
- protocol: “TCP” など
- version: “v4” など
- data
- request
- method: “GET” など
- header: “User-Agent” など
- body
- response
- header: “Content-Type” など
- body
- request
- commnication
REPEATED とは?
型ではないのですが、REPEATED という配列・繰り返しを表すモードがあります。下記のようなことを実現できます。
- STRING の repeated で文字列の配列
- INTEGER の repeated で数値の配列
- RECORD の repeated で、レコードの配列
スキーマ定義は下記のようになります。type ではなく mode に “REPEATED” と記述すると繰り返し項目ですよという意味になります。
[
{"name": "col1", "type": "STRING", "mode": "REPEATED"},
{"name": "col2", "type": "RECORD", "mode": "REPEATED", "fields": [
{"name": "subcol1", "type": "STRING", "mode": "NULLABLE"},
{"name": "subcol2", "type": "STRING", "mode": "REPEATED"}
]}
}上記は col1 STRING だけではなく、col2 RECORD も REPEATED にしています。さらに RECORD 内の col2.subcol1 も REPEATED にしました。
RECORD A 内に RECORD Asub を作った場合、以下のいずれも可能です。
- RECORD A・RECORD Asub いずれも REPEATED にしない。
- RECORD A を REPEATED、RECORD Asub は REPEATED にしない。
- RECORD A を REPEATED にせず、RECORD Asub は REPEATED にする。
- RECORD A・RECORD Asub いずれも REPEATED にする。
一意制約・UNIQUE KEY は?
BigQuery には一意制約・UNIQUE KEY はありません。あったらいいなと思うことはありますが、分散環境であるため一意であることをチェックするコストがあまりに高いということでしょう (ちなみに一意制約・UNIQUE KEY は、AWS の Redshift、Azure の SQL Data Warehouse にもありませんので、データウェアハウスとはそういうものだ、と言ってもいいのかもしれません)。
ではどうやって重複データを除去すればいいの?
これは結構難しい話題です。今取り込もうとしているデータについての重複除去であれば下記でよいでしょう。
- とりあえず重複してもよいので、データを一時的なテーブルに突っ込む (BigQuery の機能としての一時テーブルではなく、tmp_table_XXXX などの作業用テーブルという意味)。
- 一時的なテーブルにて PARTITION BY 等を駆使し、重複除去を行う。
- その結果を、結果テーブルに突っ込む。
日次バッチで、昨日到着したデータが、本日も再度現れている可能性があります。例えば IoT 機器からのデータであれば、一時的に通信状態が悪く、リトライでそのようなことが起こるケースは結構あります。そのときは…
そもそもデータ生成側で UUID などで一意なデータ作成を行うことをおすすめし…(書きかけ)
NOT NULL 制約は?
NOT NULL 制約は存在します。下記スキーマ定義の col1 は nullable なので NULL を許容します。col2 は required なので NULL 不可 (=NOT NULL) です。
[
{"name": "col1", "type": "STRING", "mode": "nullable"},
{"name": "col2", "type": "STRING", "mode": "required"}
]ただし DWH という性格上、NOT NULL とすべきかはよく考えたほうがよいでしょう。すでに他の DB で生成されたデータであることも多いでしょうから、その場合は不正データ投入防止という観点ではあまり役に立ちません (すでに他の DB には NULL が入ってしまっているため)。
NOT NULL ではじいた場合どうするのか? レコード全体を投入不可としてよいのか? むしろ NULL を許容して、不正データとしてレポートしたほうがよいのではないか? というのはよく考えたほうがよいかと思います。
外部キー制約 (参照整合性制約) は?
2021年7月現在、BigQuery に外部キー制約 (参照整合性制約) はありません。
CHECK 制約は?
2021年7月現在、BigQuery に CHECK 制約はありません。
DEFAULT 句は?
2021年7月現在、 BigQuery に DEFAULT 句はありません。実際の挙動としては、全テーブル全カラムについて DEFAULT NULL であるかのように振る舞います。
カラムのデータ型の変更はできる?
Web UI でカラムを指定して、STRING を INTEGER に変更する、というやり方はできません。ALTER 文によるデータ型変更もできません。
しかしながら下記のように DDL を使うことで比較的簡単に変更が可能です。
-- まずはテーブルを作成
CREATE TABLE `mydataset.mytable` (col1 INT64, col2 STRING)
AS SELECT 123, 'def'
-- 同じテーブル名で、カラム col1 を CAST し、自分自身を置き換え
CREATE OR REPLACE TABLE `mydataset.mytable`
AS SELECT CAST(col1 as STRING) as col1, col2 FROM `mydataset.mytable`カラムの NOT NULL の変更はできる?
required (NOT NULL) を nullable (NULL) に変更することはできます。その逆はできません。
ALTER TABLE `mydataset.mytable` ALTER CLUMNしかしながら下記のように DDL を使うことで比較的簡単に変更が可能です。
-- まずはテーブルを作成
CREATE OR REPLACE TABLE `mydataset.mytable` (col1 INT64, col2 STRING)
AS SELECT 123, 'def'
-- 同じテーブル名で、カラム col1 を CAST し、自分自身を置き換え
CREATE OR REPLACE TABLE `mydataset.mytable`
(col1 INT64 NOT NULL, col2 STRING NOT NULL)
AS SELECT col1, col2 FROM `mydataset.mytable`カラムの追加はできる?
可能です。すでにレコードが存在する場合、追加したカラムは全レコード NULL になります。カラムは先頭・中間・末尾のどこにでも追加できます (要確認)
カラムの削除はできる?
Web UI からカラムを選択して削除、ということはできません。ALTER 文でのカラム削除もできません。
しかしながら下記のように DDL を使ってテーブルを作り直すことで比較的簡単に可能です。
-- まずはテーブルを作成
CREATE TABLE `mydataset.mytable` (col1 STRING, col2 STRING)
AS SELECT 'abc', 'def'
-- 同じテーブル名で、カラム col2 を対象にしない形で、自分自身を置き換え
CREATE OR REPLACE TABLE `mydataset.mytable`
AS SELECT col1 FROM `mydataset.mytable`auto_increment なカラムを作成できる?
2021年7月現在、BigQuery で auto_increment なカラムを作成することはできません。本質的に分散処理と通番は大変相性が悪いので、今後 BigQuery に auto_increment 機能が追加される可能性は低いのではと思います。
BigQuery においては、通番より UUID のようなランダム値をおすすめします。
データセット・テーブルのメタ情報 (INFORMATION_SCHEMA編)
データセット・テーブルのメタ情報 (__TABLES__等)
INFORMATION_SCHEMA ができる前のメタ情報の取得方法も紹介しておきます。[データセット名].__TABLES__ を使います。
SELECT * FROM `myproject.mydataset.__TABLES__`
一時テーブルについて
一時テーブルとは?
BigQuery において、SELECT の結果は必ずテーブルに格納されます。宛先テーブルとしてテーブルを明示的に指定した場合はそのテーブルに、そうでない場合は「一時テーブル」(Temporary Table) に格納されます。
例えば下記のような SELECT 結果も、一時テーブルに格納されます。
SELECT * FROM mydataset.mytable WHERE col1=1下記のような参照先テーブルがまったくない SQL も同じです。一時テーブルができます。
SELECT 1上記 SELECT 1 の「ジョブ状況」タブを確認すると、下記のように「宛先テーブル: 一時テーブル」となっています。
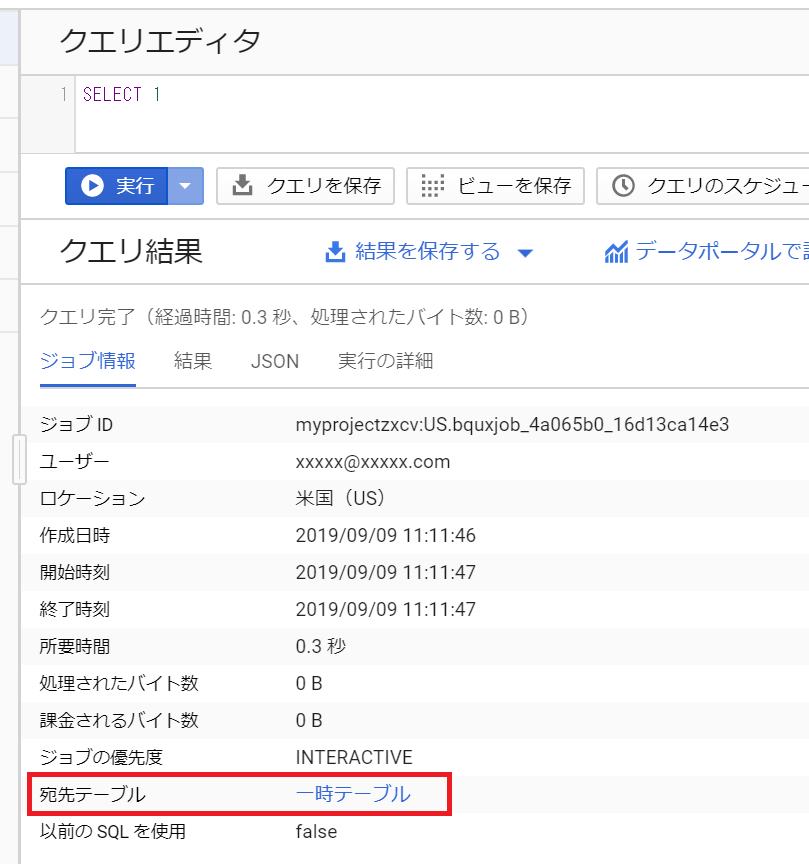
一時テーブルをクリックすると、下記のように具体的なデータセット名・テーブル名を確認することができます。一時テーブルはごく普通のテーブルなので、再度 SELECT したりすることもできます。
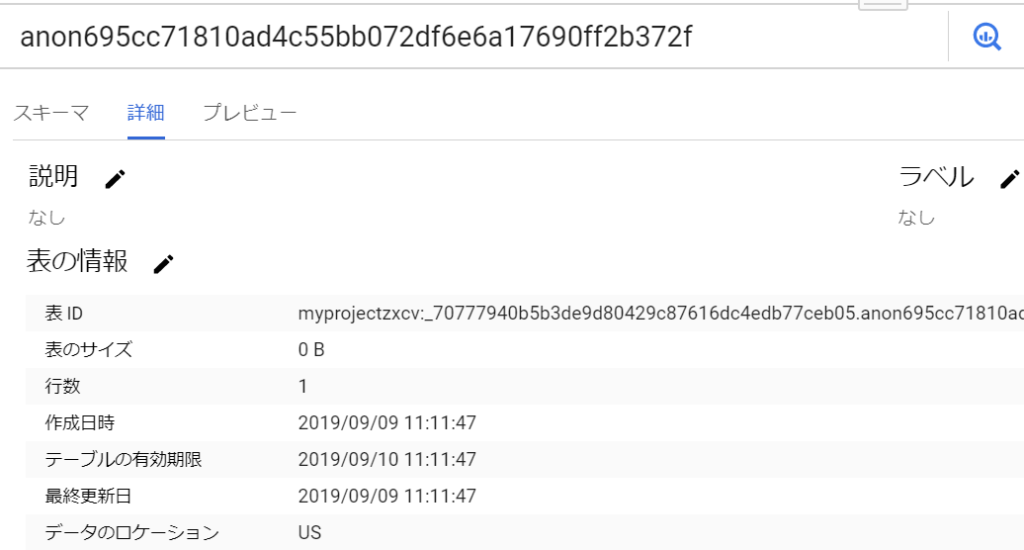
なお一時テーブルのストレージ料金は課金されません。また、一時テーブルは24時間で削除されます (作成時に 24時間後の expire 設定がなされている模様)。 一時テーブルからの SELECT は (ドキュメントには明記されていませんが) 無料のようです。
一時テーブルの便利な使い方
普通は一時テーブルを意識する必要はないのですが、便利な使い方があるので紹介します。Web アプリやバッチなどから BigQuery に対して SELECT をする場合、(宛先テーブルを指定していなければ) その結果は一時テーブルに格納されます。
トラブル発生時など、一時テーブルが作成されてから 24時間以内であれば一時テーブルの内容を確認することで、問題の切り分けが簡単に行えます。
具体的には、下記のように BigQuery Web UI の左メニュー「クエリ履歴」 → 右画面の「プロジェクト履歴」をクリックすると、そのプロジェクト内で発行されたクエリ一覧が表示されます。
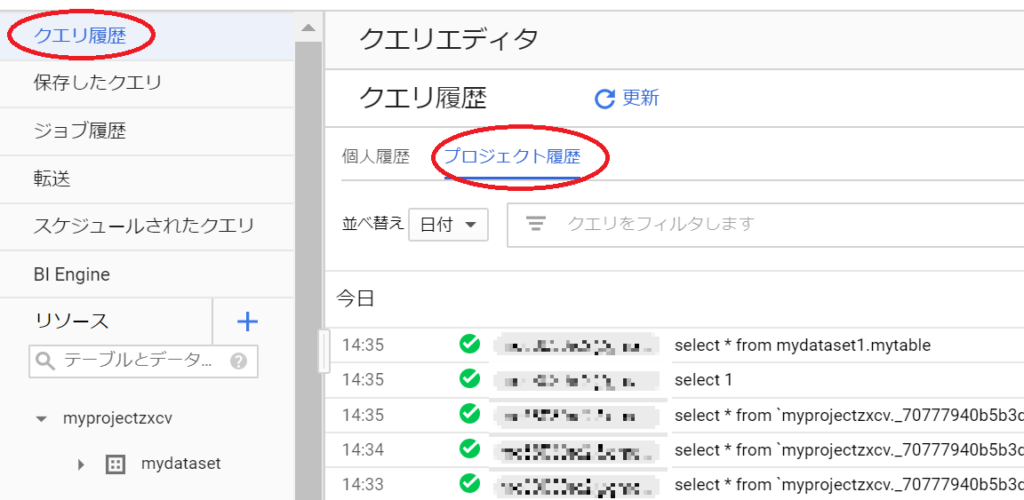
日付で絞ったりSQL 文で絞ったりして SQL を特定し、一時テーブルを参照することができます。
なお、自分以外のアカウントから作成された一時テーブルの中身を見るには、bigquery/admin ロールが必要です ★間違いでした。他のアカウントが作成した一時テーブルを見ることはできません。要修正。
SQLについて
StandardSQL・LegacySQL とは?
BigQuery のリリース時点で使えた SQL はクセがあり、あまり評判がよいとは言えませんでした。2016年に “StandardSQL” と呼ばれる規格に準拠した SQL が発表され、それに伴い従来の SQL は “LegacySQL” と命名されました。
2020年1月現在、LegacySQL は使えますし、いつ使えなくなるとアナウンスされているわけでもありませんが、StandardSQL のみで使用可能な機能が増えてきていますので、StandardSQL を使うことを強くおすすめします。
下記に、StandardSQL と LegacySQL の例をいくつかあげておきます。
-- StandardSQL はテーブル名を `` で囲む (正確にはキーワードと識別子のエスケープ時に `` を使う)。さらにプロジェクトとデータセットの区切りはドット。
SELECT col1, col2 FROM `myproject.mydatasert.mytable`
-- LegacySQL は [] で囲む。プロジェクトとデータセットの区切りはコロン。
SELECT col1, col2 FROM [myproject:mydatasert.mytable]
StandardSQL と LegacySQL の型の違い
SQLパラメータとは?
SQL インジェクション・セキュリティ対策として、SQL パラメータという仕組みがあります。ただし 2020年1月現在、 Web UI 上では 使用できません。
公式ドキュメントはこちら
SELECT 文は?
使えます。下記のように一般的な SQL が使えます。WHERE・GROUP BY・HAVING・ORDER BY・LIIMT なども使えます。
-- データセット名とテーブル名を指定
SELECT * FROM mydataset.mytable
-- プロジェクト名とデータセット名とテーブル名を指定
SELECT col1, col2 FROM myproject.mydataset.mytableSELECT に限ったことではありませんが、BigQuery ではテーブル名だけを書くとエラーになります。少なくとも「データセット名.テーブル名」は必須です。
INSERT 文は?
当初は未実装でしたが 2017年あたりから使えるようになりました。 MySQL や PostgreSQL のように複数レコードの一括投入も可能です。
-- カラム指定
INSERT INTO mydataset.mytable (col1, col2, col3) VALUES ('1', 2, 'HOGE');
-- カラム省略
INSERT INTO mydataset.mytable VALUES ('1', 2, 'HOGE');
-- 複数レコード一括投入
INSERT INTO mydataset.mytable VALUES
('1', 2, 'HOGE'),
('2', 3, 'HOGE'),
('3', 4, 'HOGE');
UPDATE 文は?
当初は未実装でしたが 2017年あたりから使えるようになりました。
なお、ストリーミングインサート直後でバッファ内にデータがあるときは UPDATE・DELETE 文は実行できません。
MERGE 文は?
StandardSQL であれば使えます。多分 Oracle と同じような MERGE 文が使用可能と考えます。
下記は from テーブルにあって to テーブルにないレコードは to テーブルにそのまま INSERT、to テーブルにすでにあるレコードは加算する例です。
MERGE `mydataset.to` t
USING `mydataset.from` f
ON t.id = f.id
WHEN MATCHED THEN
UPDATE SET value = t.value + f.value
WHEN NOT MATCHED THEN
INSERT VALUES (id, value)公式ドキュメントは こちら。
DELETE 文は?
使えます。
BigQuery の DELETE 文には WHERE 句が必須です。もし全レコードの削除をしたい場合、WHERE true や WHERE 1=1 などをつけましょう。
なお、ストリーミングインサート直後でバッファ内にデータがあるときは UPDATE・DELETE 文は実行できません。
TRUNCATE TABLE は? (2020/10より利用可能)
2020年10月より、TRUNCATE TABLE が使用可能となりました。レコードを全件削除することができます。
TRUNCATE TABLE `myproject.mydataset.mytable`ちなみに TRUNCATE TABLE がない時代は、下記のように DELETE 文でレコードをクリアしていました。DELETE は WHERE 句が必須なので、常に真となるよう WHERE true や WHERE 1=1 などと記述します。
DELETE FROM `myproject.mydataset.mytable` WHERE trueトランザクション (2021/6 より利用可能)
2021年6月より BigQuery にもトランザクションが利用可能となりました (2021年7月現在プレビュー)。
BEGIN TRANSACTION~COMMIT TRANSACTION で囲むだけです。
BEGIN TRANSACTION;
INSERT INTO `myproject.mydataset.table1` values ('a','b');
UPDATE `myproject.mydataset.table2` set col1='xx' where col2='yy';
SELECT ERROR("error test");
COMMIT TRANSACTION;上記は INSERT と UPDATE を実行するものですが、後続の SELECT ERROR(“~”) で必ずエラーが発生します。トランザクションはロールバックされますので、INSERT・UPDATE はなかったことになります。
なお、単体の SQL についてはアトミックであることが保証されており、「100万行突っ込むはずが途中でエラーが発生したため 10万行だけ成功してしまった」といったことは起こりません。エラー発生時は元の状態に戻ります。
ジョブ
ジョブって何?
BigQuery に関する操作は、すべて API を経由して行います。そのうち、実行に長時間かかる可能性のある API をジョブと定義しています (多分)。
ジョブには、クエリジョブ・読み込みジョブ (load ジョブ)・コピージョブ・エクスポートジョブの 4種類があります。
わかりづらいのですが、BigQuery の制限を把握する上で重要なので、しっかりと理解しておくことをおすすめします。
クエリジョブ
SELECT・INSERT・UPDATE・DELETE・MERGE を発行すると、クエリジョブが生成されます。bq コマンドであれば bq query 実行時に生成されます。
「クエリ (query)」とは「質問」「問い合わせ」という意味の英単語なので、本来は “SELECT” だけが対象であるべきだと当ページ管理人は考えます。BigQuery リリース直後は “SELECT” しか存在しなかったのですが、その後 INSERT・UPDATE・DELETE・MERGE が追加される際に「クエリのひとつ」として定義されたので、少しおかしな感じがします。
また、CREATE TABLE などの DDL もクエリジョブになります。
読み込みジョブ (load ジョブ)
与えられたデータを BigQuery に読み込むジョブです。これは INSERT INTO SELECT のような複雑な形式ではなく、投入すべきデータを CSV や JSON 形式でファイルとして用意しておき、それを指定したテーブルに投入するだけ、というものです。
読み込みジョブは、bq コマンドであれば bq load 実行時に生成されます。
ジョブではない BigQuery 操作とは?
データセットやテーブルの作成・一覧取得・情報取得・情報更新はジョブではありません。また、ジョブの結果 (実行中か実行完了したかなど) を取得する動作も、ジョブではありません。
要は、すぐに結果が返ってくることが期待できる操作はジョブではありません。
ジョブの実行状況を確認するには?
Web UI の左側に下記のような「クエリ履歴」「ジョブ履歴」がありますので、そこから確認できます。 「クエリ履歴」からはクエリジョブ、「ジョブ 履歴」からはクエリジョブ以外の「読み込み・コピー・エクスポートジョブ」が確認できます。
そもそもジョブの種類は下記の4つで、それぞれ並列関係なのでクエリジョブだけ特別扱いするのも変な話なのですが、使用頻度を考慮してこういう UI になっているそうです。
- クエリジョブ
- 読み込みジョブ
- コピージョブ
- エクスポートジョブ
また、コマンドラインから bq ls -j でジョブ一覧を表示することができます。bq ls -j -a で、自分以外が発行したジョブも確認できます。
分割テーブル・取り込み時間分割テーブル ・日付別テーブル
分割テーブル的なもののまとめ
Google の名前付けが下手くそすぎるので大変わかりづらいのですが、BigQuery における分割テーブル的なしくみは下記の3つがあります。
- A. 分割テーブル
- B. 取り込み時間分割テーブル
- C. 日付別テーブル
A がもっとも新しい機能で、C がもっとも古くからある機能です。おすすめは A で、B はもう使う必要なし、C は状況によっては使ってもいいかもしれない、と当ページ管理人は考えます。
分割テーブルとは?
BigQuery の分割テーブルは、世の中の RDBMS で言うところのパーティションテーブルと言ってよいでしょう。
分割テーブルは特定カラムをキーとして、内部的にテーブルを分割しておく仕組みです。
一般的な RDBMS ではパーティションのキーには任意のカラムを指定できます (例えば売上日とか、法人コードなど)。一方、BigQuery の分割テーブルのキーは TIMESTAMP または DATE のカラムのみです (2019年12月、Integer の Range パーティションが beta とのことです)。
取り込み時間分割テーブルとは?
取り込み時間分割テーブルとは、分割テーブルの前に登場したもので、パーティションのキーが「取り込み時間」の固定となっている分割テーブルです。
分割テーブルは、利用者が「このカラムをパーティションキーとせよ」と指定できますが、 取り込み時間分割テーブル は「パーティションキーは _PARTITIONTIME である」と決められています。
日付別テーブルとは?
一般的な RDBMS において、データを 2019年のテーブル・2020年のテーブルと分割したり、月単位・日単位に分割する「水平分割」は、行わないほうがよいと言われています。
一方、BigQuery では下記のように日付別にテーブルを作成するという方法が推奨されていました。
- sales20190801
- sales20190802
- sales20190803
各日付のスキーマ定義は同じにします (カラム名や型は同じにするということ)。
その上で下記のようにテーブル名部分にワイルドカードを指定することで、sales201908 から始まるテーブルすべてを対象にクエリを実行します。
SELECT * FROM `mydataset.sales201908*`日付別テーブルの実体
日付別テーブルは、ワイルドカードで検索するときに便利なようにしたものであって、末尾を YYYYMMDD 形式とすることが重要なわけではありません。YYYYMM 形式や YYYY 形式にしてもよいですし、sales_2019_1Q などとしても別に構いません。普通はしませんが、sales_a・sales_b・sales_c としても構いません。
BigQuery の権限について
BigQuery の権限はどういうもの?
基本的には下記の 2段階の構成となっています。
- Cloud IAM による BigQuery API のアクセス制限
- データセット単位のアクセス制限・テーブル単位のアクセス制限 (テーブル単位は 2020/6 にベータリリース)
その他、カラム単位での権限設定も可能ですが、まずは基本となる上記2つの説明をします。
Cloud IAM とは?
Cloud IAM は BigQuery に限ったものではなく、GCP 全般に対して下記のような権限設定を行うものです。
- 誰が (Google アカウント・Google グループ・サービスアカウント)
- 何に対して
- 何ができるか
BigQuery に関する権限 (permission) の例を下記に提示します。
| bigquery.datasets.create | データセットを新規作成する |
| bigquery.datasets.delete | データセットを削除する |
| bigquery.datasets.get | データセットのメタデータ (最終更新日など) を取得する |
| bigquery.tables.create | テーブルを新規作成する |
| bigquery.tables.delete | テーブルを削除する |
| bigquery.tables.get | テーブルのメタデータ (最終更新日・行数・スキーマ定義など) を取得する |
| bigquery.tables.getData | テーブルの内容を取得する (SELECT) |
| bigquery.tables.list | テーブルの一覧を取得する |
| bigquery.tables.update | テーブルのメタデータ(最終更新日・スキーマ定義など) を更新する |
| bigquery.tables.updateData | テーブルの内容を更新する (UPDATE や DELETE) |
| bigquery.jobs.create | ジョブを新規作成する |
| bigquery.jobs.get | ジョブの結果を取得する |
上記の権限をつけたりつけなかったりすることで、権限を設定することができるわけです。例えば以下のような感じです。
- 開発者には上記の全権限を付与する
- 閲覧のみ可能な利用者には *.get や *.getData、jobs.create や jobs.get のみをつける (*.update や *.delete は付与しない)
しかしながら BigQuery だけでも上記以外にもたくさんの権限があり(2020/06 時点で 80 以上)、これをひとつひとつ付与していくのはとても大変です。
そこでロール (=役割) という、権限 (permission) をまとめたものがあらかじめ定義されていて、通常の運用ではロールで指定するのが一般的です。
主要なロールは以下のとおりです。
| ロール | 名称 | データ参照 | データ更新 | ジョブ実行 |
| roles/bigquery.admin | BigQuery 管理者 | ○ | ○ | ○ |
| roles/bigquery.user | BigQuery ユーザー | ○ | × | ○ |
| roles/bigquery.dataEditor | BigQuery データ編集者 | ○ | △ | × |
| roles/bigquery.dataViewer | BigQuery データ閲覧者 | ○ | × | × |
| roles/bigquery.dataOwner | BigQuery データオーナー | ○ | ○ | × |
| roles/bigquery.jobUser | BigQuery ジョブユーザー | × | × | ○ |
ロールを使うと、下記のように管理が簡単になります。
- 開発者には roles/bigquery.admin を付与して、何でもできるようにする。
- 閲覧のみ可能な利用者には roles/bigquery.user を付与する。
ロールは楽に管理するためのものですので、ロールを使わず権限のみを使うことは可能です。でも超絶めんどくさいのでロールを使った方がよいでしょう。
データセット・テーブル単位で参照可否、更新可否を設定するには?
Cloud IAM を使うことで、データ参照・データ更新などの権限を制御できます。しかしこれはあくまでどの BigQuery API を叩けるか叩けないかを決めるものですので、「この人にはこのデータセットは見せるが、この人には見せない」といった制限は Cloud IAM の範囲では実現できません。
それを行いたい場合は、データセットやテーブル単位で、誰に対して見せる見せないを個別に設定します。
データセット mydataset に対して、下記のようなロールを設定できます。
- BigQuery データ編集者
- BigQuery データ閲覧者
- BigQuery データオーナー
なお、注意点として、一部のデータセットだけ見せたい利用者には bigquery.user など全データセットが見えるロールをつけてはいけません。bigquery.user ロールがあるだけで、全データセットが見えてしまうためです。
よって、bigquery.jobUser + 見せたいデータセットに「BigQuery データ閲覧者」などの権限を付与することになります。
また、2020/6 より、データセットだけではなくテーブル単位でも権限設定が可能になりました。
このデータセットだけ参照不可、を実現するには?
残念ながら「このデータセットだけ参照不可」「このデータセットだけ更新不可」をシンプルに設定することはできません。BigQuery に限らず、GCP では 2020/6 現在、権限の引き算ができません。
よって、「見せたくないデータセットには権限を指定せず、それ以外のデータセットに権限を指定する」となります。
もしデータセットが 100個あって、そのうち 1つのデータセットのみ参照不可としたい場合は、99個のデータセットを参照可能とする必要があります。
なお、2020/6 現在一般公開されていませんが、Cloud IAM Conditions を使うと「このデータセット以外は参照可」が実現できるようになるかもしれません。
ジョブの権限とデータセット・テーブルの権限
さきほど提示したロールの一部を抜粋します。
| ロール | 名称 | データ取得 | データ更新 | ジョブ実行 |
| roles/bigquery.dataViewer | BigQuery データ閲覧者 | ○ | × | × |
| roles/bigquery.jobUser | BigQuery ジョブユーザー | × | × | ○ |
dataViewer は、データセット・テーブルを読むことはできますが、ジョブ実行はできません。jobUser は、データセット・テーブルを読むことはできませんが、ジョブ実行ができます。
BigQuery において、SELECT 文を発行するためには、データセット・テーブルの参照権限と、ジョブ実行権限の両方が必要です (SELECT 文を発行するということは、クエリジョブを新規作成する、ということです)。
よって、dataViewer のみ、または jobUser のみでは SELECT 文を実行してデータを取得することができない、となります。
では dataViewer や jobUser はなんのために存在するか。
ひとつは先にあげた、データセット・テーブル単位で見せる見せないを管理するためです。
あるユーザに jobUser ロールを設定し、参照可能なデータセット・テーブルに対して BigQueryデータ参照者ロールを付与します。これにより、特定のデータセット・テーブルしか SELECT できないユーザを作ることができます。
もうひとつは、別プロジェクトから特定データを参照させるためです。例えば下記のようになっているとします。
- myproject: 商品マスタがデータセット item に存在する
- otherproject: 購入履歴が存在する
otherproject から商品マスタを参照させるためにはどうすればよいか。otherproject のメンバに対し、myproject に対して dataViewer ロールを設定します。
こうすることで、otherproject のメンバは myproject のデータセット item を参照できますが、ジョブは otherproject で実行します。これにより、クエリコストは otherproject に請求されます。
ただしこれでは myproject の全データセットが読めてしまうので、それは見せすぎということであれば、otherproject のメンバに対し、myproject のデータセット item に対して READ 権限を設定します。
Cloud IAM とデータセット・テーブル権限の関係は?
Cloud IAM と、データセットの権限、テーブルの権限は、すべて OR です。いずれかで権限があれば、参照なり更新なりが可能です。
BigQuery のドキュメントでは「継承」と表現していて、Cloud IAM > データセット権限 > テーブル権限 という関係性があるように見えますが、2020/06 現在、Cloud IAM が上位で、データセット・テーブルに優先する、といったことはありません (将来的には、下位の設定で上位を上書きできたりするようになるのかもしれません)。
UDF・Scripting
UDFとは?
UDF とは User Definition Function の略で、Oracle・MySQL・PostgreSQL などでいうところのストアドファンクションに相当します。ただし、それらのストアドファンクションと比べると機能は劣ると思っています (後述)。
UDF は SQL UDF と、Javascript UDF があります。
以前はドキュメントには下記の通り書いてありました。
- SQL UDF
- 外部 UDF
- Javascript
- (そのうち Python など他言語が使えたりするとここに追加される)
2019年夏頃に考え方が整理されて「外部 UDF」という概念がなくなり、SQL UDF・Javascript UDF という並列関係になったようです (コードの書き方は一切変わっていません)。
SQL UDF とは?
SQL UDF の例は下記です。引数 x に 4 を足し、引数 y で割った結果を返すものです。
CREATE TEMP FUNCTION addFourAndDivide(x INT64, y INT64) AS ((x + 4) / y);
SELECT addFourAndDivide(2, 3)2019/10 頃のPersistent UDF (永続 UDF) のリリースにより、下記のように CREATE FUNCTION とすることで (CREATE TEMP FUNCTION ではなく)、SQL UDF を永続化することができるようになりました。その際、データセット名を指定する必要があります。
CREATE FUNCTION mhydataset.addFourAndDivide(x INT64, y INT64)
AS ((x + 4) / y);実行時もデータセット名が必要です。
SELECT mydataset.addFourAndDivide(2, 3)SQL UDF をどう活用するべきか?
ドキュメントにはこれができないとは書いてないので推測混じりではありますが、SQL UDF でできることは、BigQuery の SQL の関数を、若干わかりやすく書くこと、だけだと思っています。
SQL UDF 内で、新たに SELECT したりはできません。SQL UDF に渡せるのはスカラー値だけであり、複数レコードを渡すこともできません。内部でループしたりもできません。返せる値は 1つだけです。
SQL UDF を永続化したり、共有したりすることはできる?
UDF の永続化 (Persistent UDF) は 2019年4月の Google Next にて発表されたもので、2019年10月現在ベータです。この機能を使うと、毎回 UDF を定義する必要はなくなり、一度だけ定義しておけば後から使用することができます。
Javascript UDF とは?
Persistent UDF (永続 UDF) とは?
スクリプト (Scripting) とは?
端的にいうと、Oracle で言うところの PL/SQL、 PostgreSQL で言うところの PL/pgSQL、MySQL で言うところのストアドプロシージャ・ストアドファンクションです。2019年4月に Google Next にて発表されたもので、2020年1月現在ベータです。
サンプルは下記です。
-- https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting?hl=ja より
-- Declare a variable to hold names as an array.
DECLARE top_names ARRAY<STRING>;
-- Build an array of the top 100 names from the year 2017.
SET top_names = (
SELECT ARRAY_AGG(name ORDER BY number DESC LIMIT 100)
FROM `bigquery-public-data`.usa_names.usa_1910_current
WHERE year = 2017
);
-- Which names appear as words in Shakespeare's plays?
SELECT
name AS shakespeare_name
FROM UNNEST(top_names) AS name
WHERE name IN (
SELECT word
FROM `bigquery-public-data`.samples.shakespeare
);ビュー
ビューとは?
Oracle・MySQL・PostgreSQL などで一般的な、アレです。CREATE VIEW で作成します。
ビューを作成・更新するには?
BigQuery コンソールから作成
現在は DDL が使えるので、下記のように作成するのが一番簡単でしょう。
CREATE OR REPLACE VIEW `myproject.mydataset.myview`
AS SELECT * FROM `myproject.mydataset2.mytable` WHERE ...bq mk –view コマンドで作成
API で作成
ビューの権限は?
ビューにパラメータを渡せる?
下記のようなにビューにパラメータを渡すことができるかという意味であれば、誠に残念ながら 2020年5月現在、できません。
-- このようなビューは作成できません
CREATE VIEW mydataset.myview(mycol INT64) AS
SELECT * FROM myproject.mydataset.mytable
WHERE col = @mycolただ、BigQuery の特性上、仮に上記のようなことができたとしても、クエリコスト削減にはつながらないと思われます。
ビューを使って、外部から _TABLE_SUFFIX 等を指定するには?
パラメータは渡せませんが、ビューに _TABLE_SUFFIX は指定できます。下記を参考にしてください。こちらはクエリコスト削減につながります。
承認済みビューとは?
BigQuery の承認済みビュー (Authroized Views) とは、ビューに参照権限を付与し、ビューの参照先テーブルには参照権限を付与しないことで、特定のレコードやカラムのみを参照させるというものです。
「承認」とは何かというと、参照先データセットにて「このビューは正規のものであるので承認するよ」という印をつけることを「承認」と呼んでいます。「参照先データセットから承認されたビュー」ということですね。
マテリアライズド・ビュー (Materialized View) は?
2020年4月、BigQuery にマテリアライズド・ビュー (Materialized View) が beta リリースされました。通常のビューとは違い、マテリアライズドビューはクエリ結果を実際のテーブルとして保持します。よって、コスト削減と高速化につながる可能性があります。
BigQuery のマテリアライズドビューの詳細は https://cloud.google.com/bigquery/docs/materialized-views-intro?hl=ja を参照してください。ただし例によってとてもわかりづらいドキュメントですので、下記の説明一読してからオフィシャルドキュメントを読むことをおすすめします。
マテリアライズドビューを作成するには?
下記のように CREATE MATERIALIZED VIEW で作成可能です。これまでビュー作成 DDL に “MATERIALIZED” を追加しただけです。
CREATE MATERIALIZED VIEW mydataset.mview AS
SELECT id, count(*) as count
FROM mydataset.orgtable
GROUP BY idちなみに、2020年5月現在、”CREATE OR REPLACE” は使えないようです (新規作成はできるが、すでに存在する場合の置き換えはエラーになる)
BigQuery のマテリアライズドビューの更新タイミングは?
まず、BigQuery のマテリアライズドビューが返す結果は、常に最新です。元テーブルが更新されたのにマテリアライズドビューが古い情報を返す、ということは起こりません。ただ、「マテリアライズドビュー自体が常に最新」というわけでもありません。
BigQuery のマテリアライズドビューは、下記の3つの状態を持ちます。
- a. 最新状態
- b. 最新でない状態
- c. 無効 (invalid)
マテリアライズドビューを作成またはリフレッシュした直後は「a. 最新状態」です。ここでマテリアライズドビューへのクエリ結果は当然ながら最新です。
ここで元テーブルに INSERT すると、マテリアライズドビューは「b. 最新でない状態」になります。ここでマテリアライズドビューへのクエリ結果は「マテビュー + 差分情報」により生成されるため、得られる結果は最新です。
元テーブルに UPDATE や DELETE を行うと、マテリアライズドビューは「c. 無効 (invalid)」になります。このとき無効なマテリアライズドビューに対して SELECT すると、自動的に元テーブルへのクエリに変換されるため、クエリ結果は最新状態になります。
b は、差分情報については元テーブルを参照するため、追加のコストと時間がかかります。c は、元テーブルを参照するため、マテリアライズドビューによるコスト・時間削減の恩恵は全く受けられません。
BigQuery におけるリフレッシュとは?
上記の「b. 最新でない状態」または「c. 無効 (invalid)」の状態を、「a. 最新状態」にするのがリフレッシュです。
自動リフレッシュを OFF にすることもできますし、「N分おきに自動リフレッシュ」とすることもできますし、手動リフレッシュも可能です。
リフレッシュするとマテリアライズドビューが最新化され、クエリ実行時のコスト・時間が短縮されますが、リフレッシュ自体にコストがかかりますので、データ更新頻度・クエリ実行頻度を見極めてよきリフレッシュ頻度を見つけましょう。
BigQuery のマテリアライズドビューの制約は?
いろいろと制約がありますが、大きなものは下記3点。
- マテリアライズドビューにおいて集約関数が必須であること。例えば COUNT・MAX・MIN・SUM などが必須です。
- マテリアライズドビューに JOIN を含めることができない。マテリアライズドビューは、1テーブルに対してのみ使うことができます。
- マテリアライズドビューに UNNEST を含めることができない。ARRAY を展開することができません。
例えば、売上テーブルから特定店舗のデータだけを WHERE 句で引っ掛けて、SELECT * で全項目をマテリアライズドビューに格納、ということはできません (集約関数がないため)。
その他こまごまとした制約もあります。
- マテリアライズドビューは、元テーブルと同一のデータセットに作成する必要があります。よって、元テーブルは公開せず、マテリアライズドビューのみ公開する、といった権限設定はできません (BigQuery の権限設定はデータセット単位であるため)
- テーブル sales_dataYYYYMMDD に対して SELECT * FROM
sales_data*的なワイルドカード機能は、マテリアライズドビューでは使えません。大量の時系列データを扱う場合、パーティションテーブル化が必須です。 - ワイルドカードがダメなら UNION ALL はどうか、と試しましたが使えませんでした。
- 分析関数 (OVER・PARTITION BY 等) も使えません。
BigQuery マテリアライズドビューのその他の特徴は?
おもしろいのは、普通のテーブルに対するクエリであっても、マテリアライズドビューが存在した場合は自動的にそちらを使ってくれるという「スマートチューニング」という機能があります。
元テーブル orgtable が存在し、下記マテビューを作成したとします。
CREATE MATERIALIZED VIEW mydataset.mview AS
SELECT id, count(*) as count
FROM mydataset.orgtable
GROUP BY idここで元テーブル orgtable を SELECT した場合、もしマテビューで定義されたものと同じようなデータ構造を取得する場合は、マテビューが自動的に使われます。
つまり、とりあえずマテビューを作ってみて、既存クエリを一切書き換えることなく、実行速度やコストが改善するか確認できるということです。
一般公開 (パブリック) データセット
一般公開 (パブリック) データセット とは?
一般公開 (パブリック) データセットとは、誰でもアクセスできるデータセットで、BigQuery 学習用サンプルが提供されています。
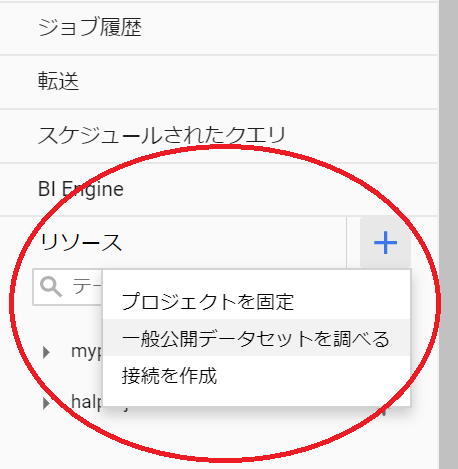
探し方は、BigQuery コンソールの左から、「リソース」の右にある「+」を押して「一般公開データセットを調べる」を選びます。
すると下記のように、様々な一般公開データセットが表示されます。
画面上部の検索フォームで、”usa names” と入力してみてください。これは米国における人名データです。

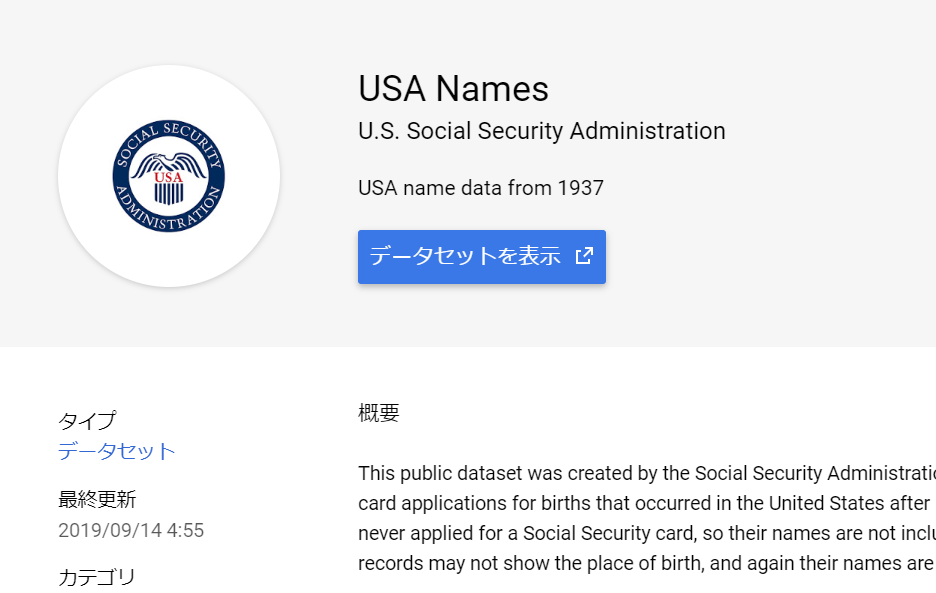
“USA Names” をクリックすると、下記のように詳細情報が表示されますので、「データセットを表示」ボタンを押します。
すると下記のような画面になります。赤丸の部分を見ると、プロジェクトが “bigquery-public-data”、データセット名が “usa_names” であることがわかるのですが、テーブル名がどこにも出ていません。
そこで画面左の検索フォームでデータセット名 “usa_names” を入力します。すると下記のように usa_1910_2013 と usa_1910_current という2テーブルがあることがわかります。
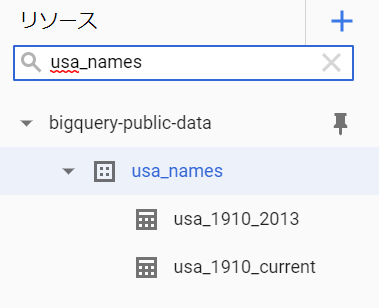
とりあえず usa_1910_2013 をクリックすると、画面右にスキーマ情報が表示されます。
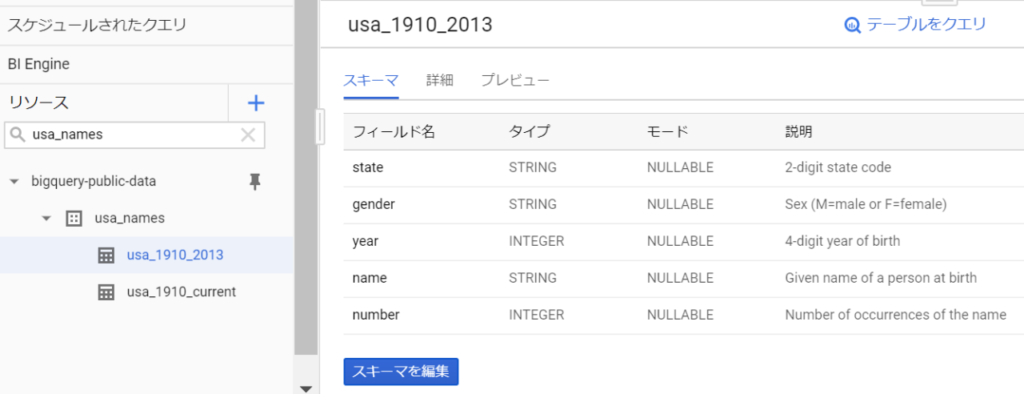
画面右の「詳細」タブを押すと、下記のようにレコード数が 555万行であることがわかります。
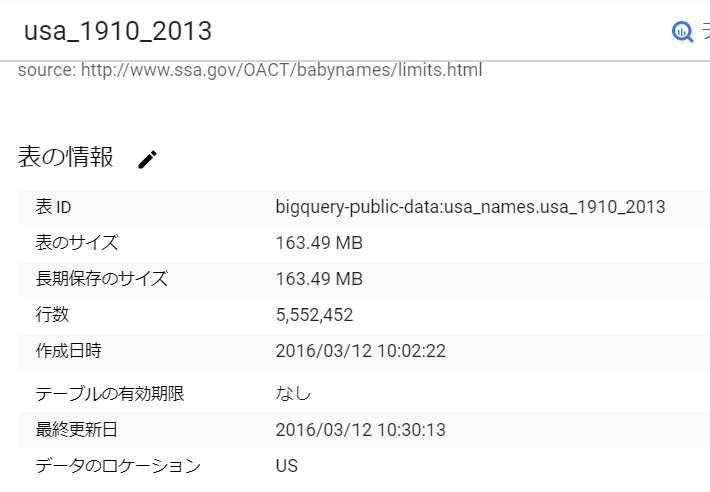
後は通常通り、クエリを実行してください。
SELECT * FROM `bigquery-public-data.usa_names.usa_1910_2013`ストレージコストはデータ提供者 (例えば Google) が支払います。クエリコストはデータ使用者 (例えばあなた) が支払います。
自分のデータセットを一般公開することはできる?
可能です。IAM 設定において、一般公開したいデータセットについて、「allAuthenticatedUsers」に対して「BigQueryデータ閲覧者」を設定します。
外部データソース
Bigtable・Cloud Storage (GCS)・
Cloud SQL federated queries
監査ログ
BigQuery に関するすべてのクエリジョブは、ログに記録されます。
Stackdriver Logging の BigQuery への連携
BigQuery は、GCP サービスのログ保管場所としても活用できます。
クエリの保存
スケジュールクエリ (Scheduled Query)
スケジュールクエリを使うと、クエリを定期的に実行することができます。
- どのような SQL を実行するか
- どのテーブルに結果を格納するか
- テーブルに追記するか、上書きするか
- 実行タイミング (毎日N時など)
- 開始日時~終了日時
- 通知結果をメールで送信するか
クラスタ
バックアップ・リストア
バックアップ・スナップショットはとれる?
BigQuery ではデータ更新が自動的に記録されているため、下記のように “@ミリ数” というスナップショットデコレータという機能を使うことで、任意時点のデータを取り出すことができます。
#legacySQL
-- 1時間前の mytable を取得
SELECT * FROM [myprojectid:mydataset.mytable@-3600000] ただし、参照可能なデータは 7日以内、削除したテーブルは 2日以内という制限があります。2019年8月現在、スナップショットデコレータを使えるのは LegacySQL のみです。StandardSQL は対応予定ありとのこと。
一方、mysqldump 的な、pg_dump 的なデータベース全体のバックアップ・スナップショットをお手軽にとりたいという意味であれば、取れません。また、1日1回などの定期的なタイミングで、バックアップ・スナップショットを自動で取得し、1ヶ月間は保存しておく、という機能も BigQuery にはありません。
どうしてもバックアップを取りたい場合、テーブル単体で bq cp で別テーブルにコピーするなり、bq export で GCS にファイルとして保存するのがよいでしょう。コピー・エクスポートは無料ですが、コピー先のテーブルのデータや GCS に保存したファイルについてはストレージ料金がかかります。
BigQuery BI Engine とは?
まず、BigQuery にデータを保存し、Tableau や Google Data Studio などの BI ツールでグラフや表形式で閲覧するというのは一般的な使い方です。ただ、BigQuery はそもそも単純な SQL でも若干の時間がかかるため、BI ツールで表示するまでに数秒、ひどいときは数十秒も時間がかかることがありました。
BigQuery BI Engine は、BigQuery 側にキャッシュなどの機構を追加し、BI ツールからアクセスする際のクエリを高速化する機能です。キャッシュ領域は 1GB 単位で確保することができ、料金は 1GB で月額 $30 程度です。キャッシュは 100GB まで設定可能です (100GB で月額 $3,000 程度)。
注意点や制限事項は下記です。
- BI Engine は、BI ツールから使う際に高速化するための仕組みです。BI ツールを使っていない場合は効果がありません。
- 2020年5月現在、対応している BI ツールは Data Studio のみです。Tableau 等は未対応です。
BI Engine リリース当初は、BigQuery のビュー・Data Studio のカスタムクエリに非対応でした (ビューに対しては高速化できず、遅いままだったということ) が、2020年2月に BigQuery のビュー・Data Studio のカスタムクエリも高速化対象にとなりました。
とりあえず月 $30 程度で試せますし、OFF にすることもできますので、軽い気持ちでやってみてはどうでしょうか。
下記の BigQuery Console の左メニュー「BI Engine」から有効化できます (適切な権限があれば)。
なお、当ページ管理人としてはテーブルへのアクセスは確かに爆速になったものの、ビューへのアクセスは遅いままなのが大変不満です。
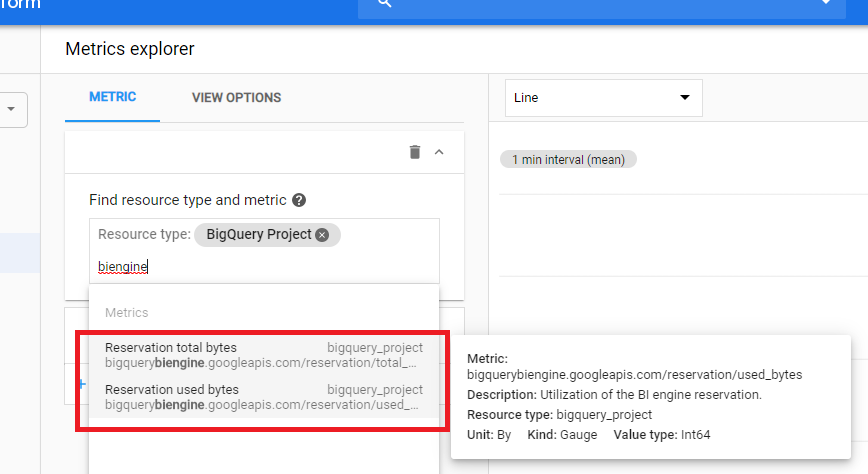
なお、Stackdriver Monitoring にて下記のようにキャッシュをどれだけ使用しているか把握できます。この例だとスカスカですね。

Metric explorer にて、フォームに “biengine” を入力すれば total bytes と used bytes が出てきますので、よい感じのグラフを作ってみてください。
有効期限・自動削除
テーブルの自動削除をするには?
BigQuery ではテーブルを自動的に削除する機能が備わっています。ただ、細かなところで挙動が異なるので注意が必要です。
まず、テーブルには有効期限を設定することができます。指定した時刻を過ぎるとテーブルは削除されます。下記は 3600秒後 (=1時間後) に削除という設定を行います。
bq mk --expiration=3600 mydataset.mytable一度設定した有効期限設定を変更・削除するには
bq update にて更新できます。
bq update --expiration=7200 mydataset.mytable有効期限設定を削除する (自動削除されないようにする) には、0 を設定します。
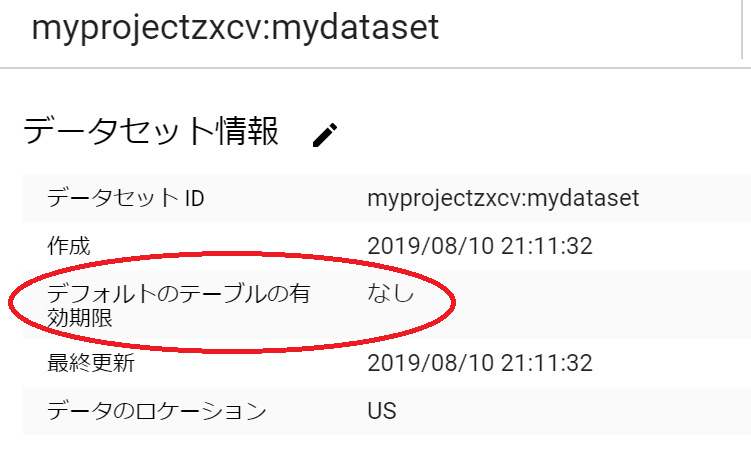
bq update --expiration=0 mydataset.mytableデータセットの「デフォルトのテーブルの有効期限」とは
データセットごとに、「デフォルトのテーブルの有効期限」を設定することができます。これは「新しいテーブルを作成する際、そのテーブルに自動的に設定するデフォルトの有効期限」です。
あくまでデフォルトですので、テーブル作成時に異なる有効期限を指定することもできます。また、テーブルがすでに存在する状態でこの有効期限を設定しても、既存テーブルには影響を与えません。
つまりこういうことです。
- デフォルトのテーブルの有効期限が 10日であるデータセットの下に、2019/08/01 に新規テーブルを作成した → そのテーブルの有効期限は 2019/08/11 となる。
- 同様に、2019/08/21 に新規テーブルを作成した → 有効期限は 8/31 となる。
- 同様に、2019/08/21 に新規テーブルを作成したが、有効期限は 3日後と指定した → デフォルトの有効期限よりも個別指定の方が優先されるので、有効期限は 8/24 となる。
テーブルではなく、レコードの自動削除はできないの?
下記のようなものをお探しであるなら、そのようなことを自動で行う機能はありません。
DELETE FROM mydataset.mytable WHERE insert_date < xxxxただし、上記 SQL をスケジュールクエリにて定期実行するという案はあると思います。
日付別テーブルの有効期限
日付別テーブル (hoge_YYYYMMDD) について、「デフォルトのテーブル有効期限」を使って削除する場合の注意点です。
hoge_YYYYMMDD テーブルが作成されたときに、「そのN日後に削除される」という設定が自動的に行われるだけで、「テーブル名末尾のYYYYMMDD が何日前か」を判断してくれているわけではない、ということに注意しましょう。
例えば初期データ投入のために1年分の365テーブルを一括作成したりすると、N日後365テーブルが一度に消えてしまいます。これを避けるには、365テーブルを作成した後に、それぞれについて適切な残り秒数を計算して、bq update –expiration=xxx を設定します。
分割テーブルの有効期限
分割テーブルについて、パーティションそれぞれに有効期限を設定することもできます。
分割テーブルの有効期限は、日付分割テーブル (hoge_YYYYMMDD) とは異なり、パーティションを作成した日時起点ではなく、パーティションキーの日付起点となります。
データセットの有効期限
2021年3月現在、データセットの自動削除機能はありません。
トリガについて
Oracle・MySQL・PostgreSQL いずれも、CREATE TRIGGER 文でトリガを作成できますが、2021年3月現在、BigQuery にはトリガはありません。
トリガとは、テーブルAにデータが INSERT・UPDATE・DELETE されたら、トリガにより何らかの SQL を発行するものです。よく使われる例としては下記です。
- 集計結果を更新する (売上テーブルに INSERT したら、月別売上テーブルにも加算するなど)。
- ログを記録する。
- 履歴テーブルに変更前の行を追加する。
BigQuery においては上記はトリガで実現することはできませんので、アプリケーション側で複数回 SQL を実行するなどの対応を取りましょう。
そもそも BigQuery は 1レコード単位で何度も同じテーブルを更新することは、不得意ですので、1時間に一回集計や日次集計にしたりするなどの工夫をしたほうがよいと思います。
BigQuery Data Transfer Service
料金
BigQuery の料金の概要
いろいろな料金の種類がありますが、主なものはクエリ料金・ストレージ料金です。
クエリ料金とは?
クエリ料金は SELECT 文を実行したときにかかる料金です。
具体的な金額はロケーションによって異なりますが、データ処理量に比例して料金がかかります。
- 東京: $6 / 1TB
- US・EU: $5 / 1TB
データ処理量とは、
SELECT col FROM mytable という SQL があるとして、
- mytable の col 列が例えば INTEGER であるとすると、INTEGER のデータサイズは 8バイト。
- それが 1000万レコードあったとすると、この SQL のデータ処理量は 76MB (8バイト×1000万レコード)。
- SQL ごとのデータ処理量を積算し、1TB あたり $6 の料金を請求。
ということです。なお、1TB 未満であれば請求なしというわけではなく、例えばデータ処理量が 76MB の場合、約 0.047円となります。このような SQL を 100回実行すると、約 4.7円というわけです。
ストレージ料金とは?
テーブルにデータを保存したままにしておくと、その容量に応じてストレージ料金がかかります。テーブルに格納した直後は「アクティブストレージ」という状態で、下記の料金がかかります。
- 東京: $0.023/GB (≒2,590円/TB)
- US/EU: $0.02/GB (≒2,252円/TB)
90日更新しなかったテーブルは、「長期保存」と呼ばれる状態になり、ストレージ料金が 50~70% になります (率はロケーションにより異なる)。これはお得な仕組みですのでぜひ活用しましょう。
アクティブストレージと長期保存について詳しく教えて
新規で作成したテーブルは必ず「アクティブストレージ」です。
テーブル内容に 90日間変更を加えなかった場合、「長期保存」に変わり、それ以降のストレージ料金が安くなります。もしテーブル内容を加えた場合、また「アクティブストレージ」に戻ります。その後も、90日間変更を加えなかった場合、再度「長期保存」に変わります。
長期保存にするためには?
下記をしないようにします。
- 読み込みジョブの実行 (bq load など。追記も含む)
- コピージョブの実行 (bq cp など。追記も含む)
- INSERT・UPDATE・DELETE・MERGE などの DML の実行
- CREATE OR REPLACE TABLE によるテーブルの置き換え
- ストリーミングインサートによるレコード追加
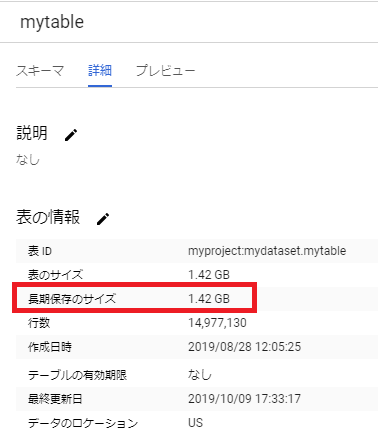
アクティブストレージか長期保存か判断する方法は?
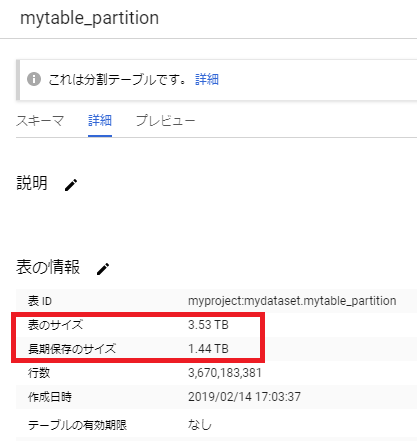
BigQuery Console から、テーブルの「詳細」を見るのが簡単です。通常のテーブルで長期保存ならば「長期保存のサイズ」が表示されています。
下記はパーティションテーブルの例です。日付でパーティション分割をした結果、90日以上前のパーティションは長期保存、それより最近のパーティションはアクティブストレージになっているので、「表のうち一部が長期保存」という表示になります。
データ投入の料金は?
bq load などによる読み込みジョブは無料です (読み込んだあとにストレージ料金はかかります)。
bq –destination_table=’mydataset.mytable’ ‘SELECT * FROM xxxx’ はクエリジョブなので SELECT 部分についてはクエリコストがかかりますが、mydataset.mytable へのデータ投入は無料です。
bq cp などによるテーブルコピーは無料です。
コスト上限設定
その1:プロジェクト単位でのカスタムコスト
その2:ユーザ単位のカスタムコスト
その3: クエリ単位の課金上限バイト数設定
BigQuery では、クエリ単位で課金上限バイト数を設定することができます。
BigQuery Console であれば、下記の「その他」>「クエリの設定」を選ぶと、
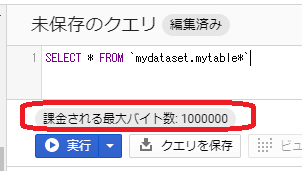
下記のようなクエリ設定画面が開きます。画面一番下の「詳細オプション」を展開すると、「課金される最大バイト数」の入力欄があります。ここに「これを超えた場合はクエリを失敗としてほしい」というバイト数を入力します。

すると下記のように表示されます。この例だと 1MB 弱ですね。
それを超えた場合、下記のようなエラーになります。この場合の料金は請求されません。

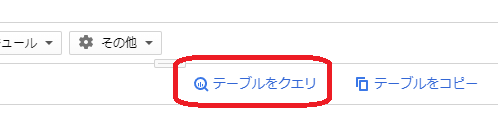
しかしながら、現在の BigQuery Console では、例えば下記の「テーブルをクエリ」ボタンを押すだけでこの制限が解除されてしまうなど、高額請求の防止策としては全く心もとない感じです。
これは Console の機能ではなく、BigQuery のクエリ実行において、上限バイト数設定ができるようになっています。よって、bq コマンドにて下記のように制限をかけることも可能です。
bq query --maximum_bytes_billed=100000000 "select ..." 本機能の公式ドキュメントは こちら。
サンドボックス
制限・制約
PaaS サービスなので、さまざまな制限・制約があります。Oracle・MySQL・PostgreSQL と同様に考えていると痛い目にあいます。特にテーブル更新などの頻度についてよく検討することをおすすめします。
ノウハウ:BigQuery にデータを投入する方法一覧
bq load コマンド
もっともシンプルで簡単なのは bq load コマンドを使うことだと思います。
Pub/Sub → ストリーミングインサート
BigQuery のストリーミングインサートを使うことで、ほぼリアルタイムに BigQuery のテーブルにデータを投入できます。
なお、GCP 無料枠ではストリーミングインサートは使えません。
DataProc → BigQuery
Cloud Storage → BigQuery
S3 → Storage Transfer Service → GCS → BigQuery
S3 → Dataflow → BigQuery
Cloud Data Fusion → BigQuery
ノウハウ:BigQuery からデータを取得する方法一覧
bq query コマンド
bq export コマンド
BigQuery Storage API
memo: dataset copy