最終更新
目次
- 1 このページは
- 2 Terraform とは
- 3 Terraform インストール
- 4 Terraform をはじめてみよう
- 5 環境変数等設定
- 6 terraform init で初期化
- 7 terraform plan
- 8 terraform apply で環境構築
- 9 もう一回 apply
- 10 tfstate とは
- 11 tfstate を消してみる
- 12 destory で全部消す
- 13 tf ファイル名のルール
- 14 リソースタイプとリソース名
- 15 「リソース名」を変更するとどうなるか
- 16 「リソース名」を変更するとどうなるか の続き (タイミング次第で挙動が変わる)
- 17 Terraform の鉄則:エラーになったら再実行
- 18 リソース名の付け方
- 19 リソースのドキュメント
- 20 argument と block と不親切なエラーメッセージ
- 21 Variable で変数にする
- 22 Variable の指定方法
- 23 他リソースを参照する
- 24 どこまで Terraform で作るべきか
- 25 fmt で整形
- 26 ログ確認
- 27 backend で S3 や GCS に tfstate を置く
- 28 data source で既存リソース参照
- 29 random の使いみち (パスワード生成編)
- 30 random の使いみち (一意なリソースを作る編)
- 31 count とは
- 32 count で配列 (おすすめしない)
- 33 count で配列 (map 編) (おすすめしない)
- 34 count のよくないところ
- 35 for_each で配列
- 36 output
- 37 random とは
- 38 if 文がないので count を使う
- 39 terraform のバージョン、provider バージョン
- 40 ドキュメントの読み方
- 41 tfenv
- 42 古い provider を使ってみる
- 43 tfstate のバージョンが意図せずあがったとき
- 44 terraform を途中で殺して lockfile を残す
- 45 module
- 46 import
- 47 taint
- 48 override
- 49 depends_on
- 50 external datasource でコマンド実行結果
- 51 lifecycle ignore changes
- 52 terraform state mv
- 53 dynamic block
- 54 templatefile
- 55 variable validation
- 56 ignore_changes
- 57 workspace
- 58 tflint
- 59 provider の alias
- 60 override
- 61 sleep
- 62 循環参照エラー
- 63 GCP IAM 設定をばっさり消した話
- 64 apply するたびにリソースを作り直してしまう話
- 65 記述順は問わないはずだが、override のときはそうでもないかもしれない話
- 66 Provider の CHANGELOG
このページは
Terraform という大変わかりづらくハマりやすい環境構築ツールで人生を浪費する人を減らすため、Terraform に対する愛情をこめて書きました。
Terraform とは
略
Terraform インストール
ここでは GCP の Cloud Shell を使う前提とします。Terraform はすでにインストールされています。
AWS など、Cloud Shell 以外の設定はいつか書きます。
Terraform をはじめてみよう
tf ファイルというものを作成します。
名前は何でもいいのですが、main.tf にしましょう。
# main.tf
provider "google" {
}
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}provider “google” とは、google という provider を使いますよということです。
では provider とは何かというと、GCP の環境構築をしたい場合、結局は GCP の API を叩くことになるわけですが、tf ファイルと API の橋渡しをしてくれrのが provider と考えてください。
- AWS であれば provider “aws”
- Azure であれば provider “azurerm”
となります。
provider の一覧は https://registry.terraform.io/browse/providers を参照してください。
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}これは GCS バケット mybucket223344 を作成する、という定義です。
環境変数等設定
本ページではプロジェクト名などを tf ファイルにベタ書きにしていません。Cloud Shell 起動後、下記のように GCP project 名を設定してください。
$ gcloud config set project myproject
$ export GOOGLE_CLOUD_PROJECT=myprojectterraform init で初期化
terraform init で初期化します。
$ terraform init
Initializing the backend...
Initializing provider plugins...
(略)
Terraform has been successfully initialized!
(略)成功した感のあるメッセージが出れば OK です。
terraform plan
terraform plan で、お試し実行ができます。実際に環境構築をせず、何が起こるかを事前に確認するだけです。
$ terraform plan
(略)
Terraform will perform the following actions:
# google_storage_bucket.mybucket will be created
+ resource "google_storage_bucket" "mybucket" {
+ bucket_policy_only = (known after apply)
+ force_destroy = false
+ id = (known after apply)
+ location = "US"
+ name = "mybucket223344"
+ project = (known after apply)
+ self_link = (known after apply)
+ storage_class = "STANDARD"
+ url = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
(略)まず見るべきポイントは “Plan: 1 to add, 0 to change, 0 to destroy.” です。
「1つのリソースを新規追加します」とありますので、それが意図通りか確認しましょう。
実際には実行しませんよ~~といいつつ、plan するだけで tfstate のバージョンがあがったりするというお茶目なところもあります。
terraform apply で環境構築
実際に構築するには terraform apply を実行します。
$ terraform apply
(略)
# google_storage_bucket.mybucket will be created
+ resource "google_storage_bucket" "mybucket" {
+ bucket_policy_only = (known after apply)
+ force_destroy = false
+ id = (known after apply)
+ location = "US"
+ name = "mybucket223344"
+ project = (known after apply)
+ self_link = (known after apply)
+ storage_class = "STANDARD"
+ url = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: plan と同じふうに出力されますね。しかし最後に、実際に実行してよいか確認されますので、ここで yes を入力します。y じゃダメです。yes です。
そうすると下記のようにバケットが作成されます。
Enter a value: yes
google_storage_bucket.mybucket: Creating...
google_storage_bucket.mybucket: Creation complete after 2s [id=mybucket223344]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.もう一回 apply
GCS バケットが存在する状態で、もう一度 apply します。
$ terraform apply
google_storage_bucket.mybucket: Refreshing state... [id=mybucket223344]
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.すると何もせず終了します。main.tf に書かれているリソースはすでに存在するので、何もやるべきことがない、ということですね。
tfstate とは
カレントディレクトリに terraform.tfstate というファイルが生成されていることと思います。
{
"version": 4,
"terraform_version": "0.12.24",
"serial": 3,
"lineage": "f7e1c4a6-4473-5111-ace3-f1d48edaa7e6",
"resources": [
{
"mode": "managed",
"type": "google_storage_bucket",
"name": "mybucket",
"provider": "provider.google",
"instances": [
{
"schema_version": 0,
"attributes": {
"name": "mybucket223344",
(略)
"storage_class": "STANDARD",
"versioning": [],
"website": []
(略)
},
}
]
}
]
}tfstate を消してみる
GCS バケットが存在する状態で、tfstate ファイルを削除してみましょう。
$ rm terraform.tfstateそして terraform apply とします。なんと、Terraform 氏は GCS バケットがないものと判断し、作成しようとするんですね。
terraform apply
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# google_storage_bucket.mybucket will be created
+ resource "google_storage_bucket" "mybucket" {
+ bucket_policy_only = (known after apply)
+ force_destroy = false
+ id = (known after apply)
+ location = "US"
+ name = "mybucket223344"
+ project = (known after apply)
+ self_link = (known after apply)
+ storage_class = "STANDARD"
+ url = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.ここで yes としてみます。するとどうなるか。
Enter a value: yes
google_storage_bucket.mybucket: Creating...
Error: googleapi: Error 409: You already own this bucket. Please select another name., conflict
on main.tf line 3, in resource "google_storage_bucket" "mybucket":
3: resource "google_storage_bucket" "mybucket" {GCS バケットを作成しようとしますが、すでに同名のバケットが存在するのでエラーとなります。
いやいや、そんなのいい感じに処理してよ!と思うのですが、どうにもなりません。tfstate ファイルは命より大事なものとして扱いましょう。
こういう場合はどうするかというと、terraform import するのですが、今回はめんどくさいので gsutil コマンドでバケットを削除します。
$ gsutil rb gs://mybucket223344
Removing gs://mybucket223344/...destory で全部消す
terraform で作成したリソースは、destroy で全部消すことができます。
$ terraform destroy
(略)
# google_storage_bucket.mybucket will be destroyed
- resource "google_storage_bucket" "mybucket" {
- bucket_policy_only = false -> null
- default_event_based_hold = false -> null
- force_destroy = false -> null
- id = "mybucket223344" -> null
- labels = {} -> null
- location = "US" -> null
- name = "mybucket223344" -> null
- requester_pays = false -> null
- self_link = "https://www.googleapis.com/storage/v1/b/mybucket223344" -> null
- storage_class = "STANDARD" -> null
- url = "gs://mybucket223344" -> null
}
Plan: 0 to add, 0 to change, 1 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value:tf ファイル名のルール
上記の例では main.tf というファイル名に provider と resource を記述しました。
実はこの main.tf というファイル名には何の意味もありません。hoge.tf でもいいです。拡張子が .tf であればなんでもアリです。
また、下記のように provider.tf と main.tf に分けるのもアリでしょう。provider.tf と gcs.tf でもよいです。ファイル名にルールはありませんので、分割するとしても a.tf と b.tf としても動きます。
# provider.tf
provider "google" {
}# main.tf
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}上記のようなファイル名変更・ファイル分割/統合は、apply してリソースを作成した後で行っても挙動に変化はありません。
ただ、a.tf、b.tf でも動きはしますが、わかりづらいので当然ながらおすすめはしません。
リソースタイプとリソース名
下記のような記述全体を「リソースブロック」と言います。
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}google_storage_bucket はリソースタイプと呼び、これは予め定義されたものでなくてはなりません。ここを変えるとそんなリソースタイプはないと言われ、動かなくなります。
一方 mybucket は「リソース名」(resource name)、「名前」(name) あるいは「ローカル名」(local name) と呼ぶらしく、好きな名前をつけることができます。mybucket・bucket・hoge・a・b なんでもアリです。
ただし同じ名称はつかえません。下記のように リソース名 mybucket が重複するとエラーとなります。
resource "google_storage_bucket" "mybucket" {
name = "mybucket1"
}
resource "google_storage_bucket" "mybucket" {
name = "mybucket2"
}「リソース名」を変更するとどうなるか
下記のリソース名 mybucket を変更するとどうなるか。
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}apply 前であれば何の問題もありません。
しかし apply して実際に GCS バケットが生成され、tfstate が生成された後に、リソース名を変更するのは面倒です。
tf ファイルの mybucket を mybucket2 に変更してみましょう。
# resource "google_storage_bucket" "mybucket" {
resource "google_storage_bucket" "mybucket2" {
name = "mybucket223344"
}apply します。
$ terraform apply
(略)
# google_storage_bucket.mybucket will be destroyed
- resource "google_storage_bucket" "mybucket" {
- bucket_policy_only = false -> null
- default_event_based_hold = false -> null
- force_destroy = false -> null
- id = "mybucket223344" -> null
- labels = {} -> null
- location = "US" -> null
- name = "mybucket223344" -> null
- requester_pays = false -> null
- self_link = "https://www.googleapis.com/storage/v1/b/mybucket2233442222" -> null
- storage_class = "STANDARD" -> null
- url = "gs://mybucket2233442222" -> null
}
# google_storage_bucket.mybucket2 will be created
+ resource "google_storage_bucket" "mybucket2" {
+ bucket_policy_only = (known after apply)
+ force_destroy = false
+ id = (known after apply)
+ location = "US"
+ name = "mybucket2233442222"
+ project = (known after apply)
+ self_link = (known after apply)
+ storage_class = "STANDARD"
+ url = (known after apply)
}
Plan: 1 to add, 0 to change, 1 to destroy.
(略)
Enter a value:なんかめんどくさそうなことになっていますね。
Terraform は「リソースタイプ + リソース名」で作成済リソースを管理していますので、名前を変更した結果、
- tfstate にある mybucket が tf ファイルになくなっているが、GCS バケットとしては存在している → GCS バケット mybucket223344 を削除しよう
- tfstate にない mybucket2 が tf ファイルに追加され、GCS バケットとして存在していない → GCS バケット mybucket223344 を作成しよう
となったわけです。
ですので、「名前」はよく考えて付けましょう。
なお、terraform state mv という手もあります (後述)。
「リソース名」を変更するとどうなるか の続き (タイミング次第で挙動が変わる)
「名前を変更したいけど、削除 & 作成になるのはまぁいいや」と思っても、うまくいかない場合があります。
Terraform は依存関係を自動検出して並行処理できる部分を同時実行することで処理時間を短縮するのがウリです。
この場合、下記の2つの処理を同時実行しようとします。
- tfstate にある mybucket が tf ファイルになくなっているが、GCS バケットとしては存在している → GCS バケット mybucket223344 を削除しよう
- tfstate にない mybucket2 が tf ファイルに追加され、GCS バケットとして存在していない → GCS バケット mybucket223344 を作成しよう
しかしながら、GCS バケット名は一意である必要がありますので、すでに存在しているバケットと同名のバケットを作成しようとするとエラーになりますが、削除と作成が同時に行われるため、タイミング次第で成功したり失敗したりしてしまいます。
「名前」を変更したところ、10回中3回ほど下記エラーで失敗しました。
Error: googleapi: Error 409: You already own this bucket. Please select another name., conflict
on main.tf line 3, in resource "google_storage_bucket" "mybucket2":
3: resource "google_storage_bucket" "mybucket2" {さらにいやらしいのが、仮に失敗したパターンでも「バケット削除は成功、バケット生成は失敗」という状態であるため、もう一度 apply すると成功してしまうんですね。
Terraform の鉄則:エラーになったら再実行
Terraform はとにかく謎のエラーを吐きます。有識者が見ればわかるものであっても、初心者にはまったく理解できません。
そこで当ページ管理人が編み出したテクニックは「エラーになったらとりあえずもう一度 apply」です。原因の大半は「depends_on 不足」「クラウド側の API の裏側で処理が続行している」な気がするのですが、再現性がないので原因究明ができない (何しろもう一度実行したら成功してしまうのだから)。
Terraform に詳しくなるまでは、「エラー → 再実行」と意識低くいきましょう。
リソース名の付け方
よくあるのが “default” です。リソース名を感上げるのがめんどくさいときにおすすめです。しかしながら、1つしか作らないと思っていた同じタイプのリソースを複数作ることになった場合は面倒になります。
resource "google_storage_bucket" "default" {
name = "バケット名"
}実際に作成される名前 (下記例だとバケット名) を一致させるというのもあります。
resource "google_storage_bucket" "mybucket" {
name = "mybucket"
}リソースのドキュメント
GCS バケットのリソースタイプ google_storage_bucket のドキュメントは下記です。
https://registry.terraform.io/providers/hashicorp/google/latest/docs/resources/storage_bucket
ここにはリソースタイプ google_storage_bucket で使える記述が全部載っています。
気をつけるべきなのは画面日取り上にあるバージョンです。
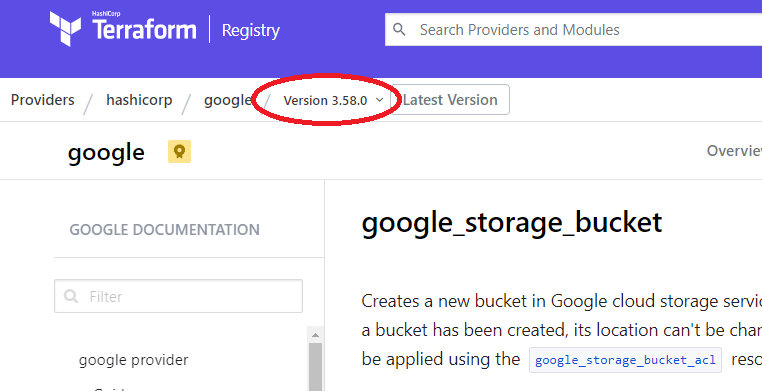
このドキュメントは provider “google” のバージョン 3.58.0 に基づく記述であることがわかります。
一方、2021/02/24 に当ページ管理人の Cloud Shell 上で terrraform version にて provider “google” のバージョンを確認したところ、3.7.0 とのこと。
$ terraform version
Terraform v0.12.24
+ provider.google v3.7.0provider “google” の CHANGELOG を見ると、3.7.0 は 2020/02/03 リリースだそうなのでほぼ 1年経過しています。
https://github.com/hashicorp/terraform-provider-google/blob/master/CHANGELOG.md#370-february-03-2020
ですので当ページ管理人が見るべきページは 3.58.0 ではなく 1年前の 3.7.0 です。
(そして 3.7.0 のドキュメントに移動するのがめんどくさいという話を書く!)
argument と block と不親切なエラーメッセージ
resource に限った話ではないのですが、argument と block の違いに注意しましょう。下記では、”resource” はブロック、”name” は argument、”versioning” はブロックです。
resource "google_storage_bucket" "mybucket" {
name = "mybucket"
versioning {
enabled = true
}
}ここで “versioning = {” と間にイコールを付けてしまうと、下記のように初心者にはわかりづらい親切なメッセージで Terraform 様にお教えいただけます。
Error: Unsupported argument
on main.tf line 19, in resource "google_storage_bucket" "mybucket":
19: versioning = {
An argument named "versioning" is not expected here. Did you mean to define a block of type "versioning"?「versioning はここでは使えないけど、もしかして versioning のこと?」と言われているように読めて、なんのこっちゃとなります。
わかっている人が読むと、「argument じゃなくて block のこと? (であれば = はいらないよ)」かもしれませんが、こんなんわかるか!
Variable で変数にする
あとから変更したくなるような部分、例えばプロジェクト名・インスタンス数・マシンタイプなど、variable として変数化しておくことをおすすめします。
たとえばこんな感じで GCE インスタンスを作成しようとしていたとして、
resource "google_compute_instance" "default" {
name = "myinstance"
machine_type = "e2-standard-4"
zone = "us-central1-a"
boot_disk {
initialize_params {
size = 10
type = "pd-standard"
image = "debian-cloud/debian-9"
}
}
}variable に切り出すとこうなります。
# gce.tf
resource "google_compute_instance" "default" {
count = is_create_gce ? 1 : 0
name = "myinstance"
machine_type = var.gce_machine_type
zone = var.zone
boot_disk {
initialize_params {
size = var.gce_boot_disk_gb
type = var.gce_boot_disk_type
image = "debian-cloud/debian-9"
}
}
}# variables.tf
variable "gce_machine_type" {
default = "n2-standard-4" # マシンタイプ
}
variable "gce_boot_disk_gb" {
default = 20 # ブートディスク容量 (GB)
}
variable "gce_boot_disk_type" {
default = "pd-standard" # HDD ではなく SSD にしたいなら pd-ssd にする
}
variable "is_create_gce" {
default = true # GCE作成しないなら false にする
}Variable の指定方法
variable にて default 値が指定されているなら、特に何も指定しない場合、default 値が使われます。
variable を変更したいときの方法を下記に示します。
方法1: variables.tf などに書かれている variable ブロックを直接編集する。
方法2: terraform apply にて -var オプションを指定する
$ terrarofm apply -var gce_boot_disk_gb=40 -var gce_boot_disk_type=pd-ssd方法3:terraform.tfvars ファイルに記述しておく
$ cat terraform.tfvars
gce_boot_disk_gb=40
gce_boot_disk_type="pd-ssd"方法4:hoge.tfvars に記述し、-var-file hoge.tfvars で指定する
例えば dev.tfvars、stg,tfvars、prod.tfvars と環境別に tfvars ファイルを作成し、環境名で切り分けたりします。
方法5:default や tfvars で定義されていない場合、コマンドラインで入力する。
他リソースを参照する
どこまで Terraform で作るべきか
fmt で整形
ログ確認
backend で S3 や GCS に tfstate を置く
data source で既存リソース参照
random の使いみち (パスワード生成編)
random の使いみち (一意なリソースを作る編)
count とは
Terraform には count という繰り返し同じものを作る仕組みがあります。
例えば下記は GCS バケットを生成しますが、
resource "google_storage_bucket" "mybucket" {
name = "mybucket223344"
}count = 2 とすると、2つ作ってくれます。
resource "google_storage_bucket" "mybucket" {
count = 2
name = "mybucket123"
}しかしながら上記はエラーになります。1つめは成功するとしても、2つめを作る時点で mybucket123 という名前が重複するからですね。
count で配列 (おすすめしない)
典型的な使い方は下記のようにします。variable で配列を定義し、その要素数を count に設定、name には mybuckets の N 番目、というのを指定します。
variable "mybuckets" {
default = ["mybucket123-0", "mybucket123-1", "mybucket123-2"]
}
resource "google_storage_bucket" "mybucket" {
count = length( var.mybuckets )
name = element(var.mybuckets, count.index)
}count で配列 (map 編) (おすすめしない)
複数のリソースを作成するけれども、リソースによって設定値を買えたい場合があります。例えば GCS バケットを複数作成するが、一部のみバージョニングを ON にする場合。例えば GCE インスタンスを複数作成するが、マシンタイプが異なる場合。
そのようなときは単純な配列ではなく、map 形式で variable を定義します。
シンプルなのは例1で、めんどくさいのは例3なのですが、ネット上に例3の記述があるということは古い Terraform では例1 の書き方ができなかったのかもしれません。
例1:配列の中に map
variable "mybuckets" {
default = [
{
name="backup"
versioning = true
},
{
name="deploy"
versioning = false
}
]
}
resource "google_storage_bucket" "mybucket" {
count = length(var.mybuckets)
name = "hogehogexx-${var.mybuckets[count.index].name}"
versioning {
enabled = var.mybuckets[count.index].versioning
}
}例2:mapの中に配列、その中に map
variable "mybuckets" {
default = {
params = [
{
name="backup"
versioning = true
},
{
name="deploy"
versioning = false
}
]
}
}
resource "google_storage_bucket" "mybucket" {
count = length(var.mybuckets.params)
name = "hogehogexx-${var.mybuckets.params[count.index].name}"
versioning {
enabled = var.mybuckets.params[count.index].versioning
}
}例3: map の中に map、その中に map で、真ん中の map を values で配列化
variable "mybuckets" {
default = {
params = {
param1 = {
name="backup"
versioning = true
}
param2 ={
name="deploy"
versioning = false
}
}
}
}
resource "google_storage_bucket" "mybucket" {
count = length(var.mybuckets.params)
name = "mybuckets-${values(var.mybuckets.params)[count.index].name}"
versioning {
enabled = values(var.mybuckets.params)[count.index].versioning
}
}count のよくないところ
plan・apply の出力を見るとわかりますが、下記のように結局内部では配列構造になっているわけです。
# google_storage_bucket.mybucket[0] will be created
+ resource "google_storage_bucket" "mybucket" {
+ name = "mybucket123-0"
(略)
# google_storage_bucket.mybucket[1] will be created
+ resource "google_storage_bucket" "mybucket" {
+ name = "mybucket123-1"
(略)
# google_storage_bucket.mybucket[2] will be created
+ resource "google_storage_bucket" "mybucket" {
+ name = "mybucket123-2"
(略)
よって下記の配列の途中に要素を追加したり削除したりした場合、リソース名が変更されたことになり、途中の要素以降がすべて作り直しになってしまいます。
variable "mybuckets" {
default = ["mybucket123-0", "mybucket123-1", "mybucket123-2"]
}for_each で配列
count の追加・変更に弱い欠点を解消するのが
output
random とは
random は provider のひとつで、ランダムな文字列や数値を生成するものです。
使いみちは下記のとおりです。
- パスワードを生成する
- 名前の重複を回避するためのランダム文字列を生成する
下記のように random_id リソースを記述し、terraform apply で生成します。
# main.tf
resource "random_id" "myrandom" {
byte_length = 8
}apply した結果は terraform show で確認できます。
$ terraform show
# random_id.myrandom:
resource "random_id" "myrandom" {
b64_std = "BXxsdCUE09w="
b64_url = "BXxsdCUE09w"
byte_length = 8
dec = "395310113394840540"
hex = "057c6c742504d3dc"
id = "BXxsdCUE09w"
}値としては 1つですが、BASE64 であったり、10進数であったり、16進数であったり、いろいろな用途に使えるようになっています。
では GCS や S3 のように世界中で一意であるバケット名が必要な場合、重複を避けるために末尾にランダム文字列を設定してみましょう。
resource "random_id" "myrandom" {
byte_length = 8
}
resource "google_storage_bucket" "mybucket" {
name = "mybucket-${random_id.myrandom.hex}"
}これを apply すると、”mybucket-057c6c742504d3dc” というバケットが生成されます。
なお、random の結果は「tfstate のみ」に保存されることに注意してください (AWS や GCP などクラウドサービスにランダム情報が保持されるわけではない)。
if 文がないので count を使う
Terraform には if 文がありません。しかしながら条件判定してリソースを作る作らないをコントロールしたい場合は多々あります。
そういう場合、count を使うテクニックがあります。
といっても「下記のように count = 0 としておけば 0個作成される=何も作成されない」というだけです。
resource "google_storage_bucket" "mybucket" {
count = 0
name = "mybucket123"
}直接 count = 0 と 1 を書き換えるのもわかりづらいので、一般的には variables.tf に変数として切り出します。
下記、variables.tf の needs_backup_bucket を true にすればバケット作成、false にすればバケット作成しない、となります。
# main.tf
resource "google_storage_bucket" "mybucket" {
count = var.needs_backup_bucket ? 1 : 0
name = "mybucket123"
}# variables.tf
variable "needs_backup_bucket" {
default = true
// default = false
}terraform のバージョン、provider バージョン
ドキュメントの読み方
terraform 本体
- https://www.terraform.io/docs/index.html
- ファイル名、エンコーディング、改行コード https://www.terraform.io/docs/language/files/index.html
- argument、ブロック、コメント等 https://www.terraform.io/docs/language/syntax/configuration.html
- resource ブロック https://www.terraform.io/docs/language/resources/syntax.html
- https://www.terraform.io/docs/language/resources/behavior.html
- meta arguments (depends_on, count, for_each, provider, lifecycle) https://www.terraform.io/docs/language/resources/syntax.html#meta-arguments
- provisioner とは? https://www.terraform.io/docs/language/resources/provisioners/index.html
- data source https://www.terraform.io/docs/language/data-sources/index.html
- provider https://www.terraform.io/docs/language/providers/index.html
resource について、block の定義は画面の下にあるよ、リンクをくりっくしても block の説明には飛ばないよ!という話。
provider のドキュメントを読む。
proivider の guides を読む。
tfenv
tfenv は、異なるバージョンの terraform をインストールし、簡単に切り替えることができるツールです。
古い provider を使ってみる
tfstate のバージョンが意図せずあがったとき
terraform を途中で殺して lockfile を残す
module
Terraform の module は、複数のリソースを一度に作成するなど、「provider を使って頑張ればできるけれど、module だとより簡単にできる」という位置づけの機能です。
公開されている module を使うこともできますし、自分で module を作成することもできます。
公開されている module の例が下記です。
- GCP Project 作成と、terraform state 保存用バケット、API の有効化、バジェット使用量の通知先 Pub/Sub、共有 VPC 設定などをまとめて行う。
- BigQuery のデータセットとテーブル作成をまとめて行う。
import
taint
override
depends_on
external datasource でコマンド実行結果
lifecycle ignore changes
terraform state mv
dynamic block
templatefile
variable validation
ignore_changes
workspace
tflint
provider の alias
override
sleep
循環参照エラー
cycle error というのが出た場合、Graphviz というパッケージに含まれるグラフ情報を画像に変換する dot コマンドを使って画像化するとよいらしい。
https://qiita.com/ringo/items/d06d936209d7abd9dcff
当ページ管理人の例。つらい。
GCP IAM 設定をばっさり消した話
apply するたびにリソースを作り直してしまう話
記述順は問わないはずだが、override のときはそうでもないかもしれない話
https://limitusus.hatenablog.com/entry/2017/07/12/110343
Provider の CHANGELOG
provider AWS・Azure・GCP それぞれの CHANGELOG へのリンクを示します。いずれも基本は 1週間単位でのリリースようので、精力的な更新がなされていると考えてよいのではないでしょうか。