このページでは、GAE から、GCP のいろいろなサービスとの連携方法を説明します。
目次
GitHub リポジトリ
本ページのソースは https://github.com/68user/gcp-gae-python3-tutorial/tree/master/gae_to_gcs_services にあります。
下記手順で GitHub からソースを取得し、GAE にデプロイすることができます。本ページの説明では一部を省略していますので、このページに書かれているとおりソースに書いても動きません。動かすには GitHub からダウンロードしてください。
# ソース取得
git clone https://github.com/68user/gcp-gae-python3-tutorial.git
# GCS サービス連携用サンプルプログラム置き場に移動
cd gcp-gae-python3-tutorial/gae_to_gcs_services/
# デプロイ
gcloud app deployGAE から BigQuery を使ってみよう
BigQuery は GCP が誇るデータウェアハウスエンジンです。GCP と言えば BigQuery、と言っても過言ではありません。
サンプルとして、GAE から BigQuery に SELECT を発行し、データを取得してみましょう。
BigQuery には Google によって一般に公開されているパブリックデータセットというものがあります。この中には気象情報・株などのデータ・プロスポーツの統計結果など、様々なものが入っています。
そのパブリックデータからおもしろそうなものを取ってくる…というのをやってみたかったのですが、大量データを扱うとお金がかかるので、ここではパブリックデータセットの一覧を取得してみます。
BigQuery にアクセスする際、Python 用の Google Cloud クライアントライブラリというものを使うことにします。Cloud Shell 内にはインストール済みですが、GAE Standard Python3.7 環境には入っていませんので、requirements.txt に下記を追加しておきましょう。
google-cloud-bigquery==1.9.0ソースは以下のとおりです (抜粋)。
@app.route('/bqquery')
def do_bqquery():
from flask import render_template_string
from google.cloud import bigquery
bigquery_client = bigquery.Client()
sql = """
#StandardSQL
select * FROM
`bigquery-public-data.INFORMATION_SCHEMA`.SCHEMATA
order by schema_name
"""
query_job = bigquery_client.query(sql)
try:
results = query_job.result()
except:
return "errorResult {}".format(query_job.errorResult)
# $5 per 1TB
cost_usd = "%f" % (5 * query_job.total_bytes_billed / (1024*1024*1024*1024))
# $1 = 110 JPY
cost_jpy = "%f" % (110 * 5 * query_job.total_bytes_billed / (1024*1024*1024*1024))
return render_template_string("""
(HTMLテンプレートは略)
""",
sql = sql,
total_bytes_billed = query_job.total_bytes_billed,
job_id = query_job.job_id,
cost_usd = cost_usd,
cost_jpy = cost_jpy,
results = results)
結果は下記のようになります。
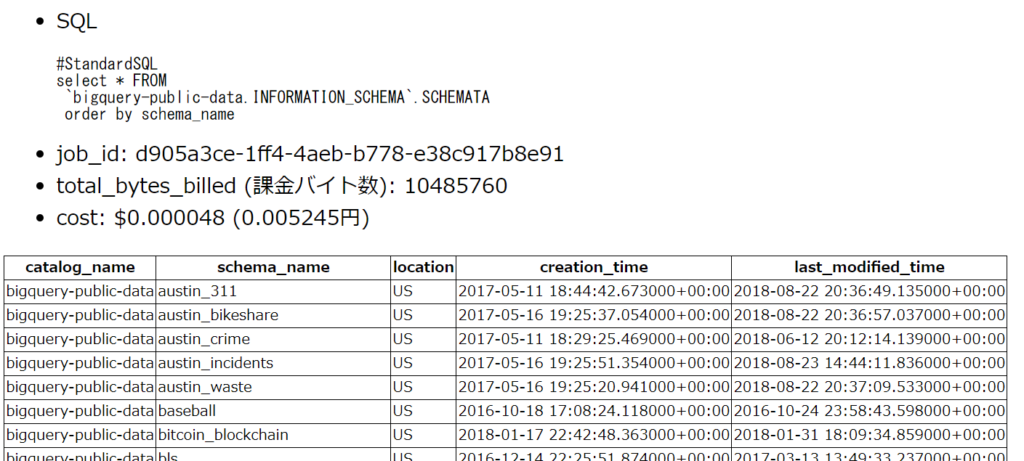
ポイントは以下のとおり。
- google.cloud.bigquery ライブラリを使います。
- bigquery_client = bigquery.Client() で、クライアント用のインスタンスを生成します。
- query_job = bigquery_client.query(“SELECT …”) で SQL 文を発行します。
- result = query_job.result() で、結果を取得します。result はイテレータで、行データが入っています。
- 実行が完了した query_job には、下記のパラメータが入っています。
- query_job.job_id:一意な JobID
- query_job.total_bytes_billed:請求金額算出に使用される課金バイト数
- エラー発生時には例外が飛んできますので、query_job.error_result にエラー情報が入っています。”SELECT …” の部分を “xxxSELECT … “などと不正な SQL に書き換えて試してみてください。
なお「GAE ならでは」な書き方は一切ありません。このコードは、GCE からでも Functions でも Cloud Shell からでも動くはずです。
GAE から Cloud Storage を使ってみよう
Cloud Storage は、オブジェクトストレージです。AWS で言うところの S3 に相当します。
BigQuery と同様に、Cloud Storage にもパブリックデータが置かれています。そのパブリックデータから、下記の処理を行うサンプルコードを作成します。
- バケットの下にある一覧を取得
- 特定のオブジェクトを取得
Cloud Storage にアクセスする際、Python 用の Google Cloud クライアントライブラリというものを使うことにします。Cloud Shell 内にはインストール済みですが、GAE Standard Python3.7 環境には入っていませんので、requirements.txt に下記を追加しておきましょう。
google-cloud-storage==1.14.0ソースは以下のとおりです (抜粋)。
@app.route('/storage')
def do_storage():
from flask import render_template_string
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket('gcp-public-data-landsat')
blob_list = bucket.list_blobs(prefix='LC08/PRE/044/034/LC80440342016259LGN00',
max_results=5)
blob = bucket.get_blob('LC08/PRE/044/034/LC80440342016259LGN00/LC80440342016259LGN00_MTL.txt')
content = blob.download_as_string().decode(encoding='ASCII')
return render_template_string("""
(HTMLテンプレートは略)
""",
blob_list = blob_list,
bucket = blob.bucket.name,
name = blob.name,
size = blob.size,
content = content)実行結果は下記です。
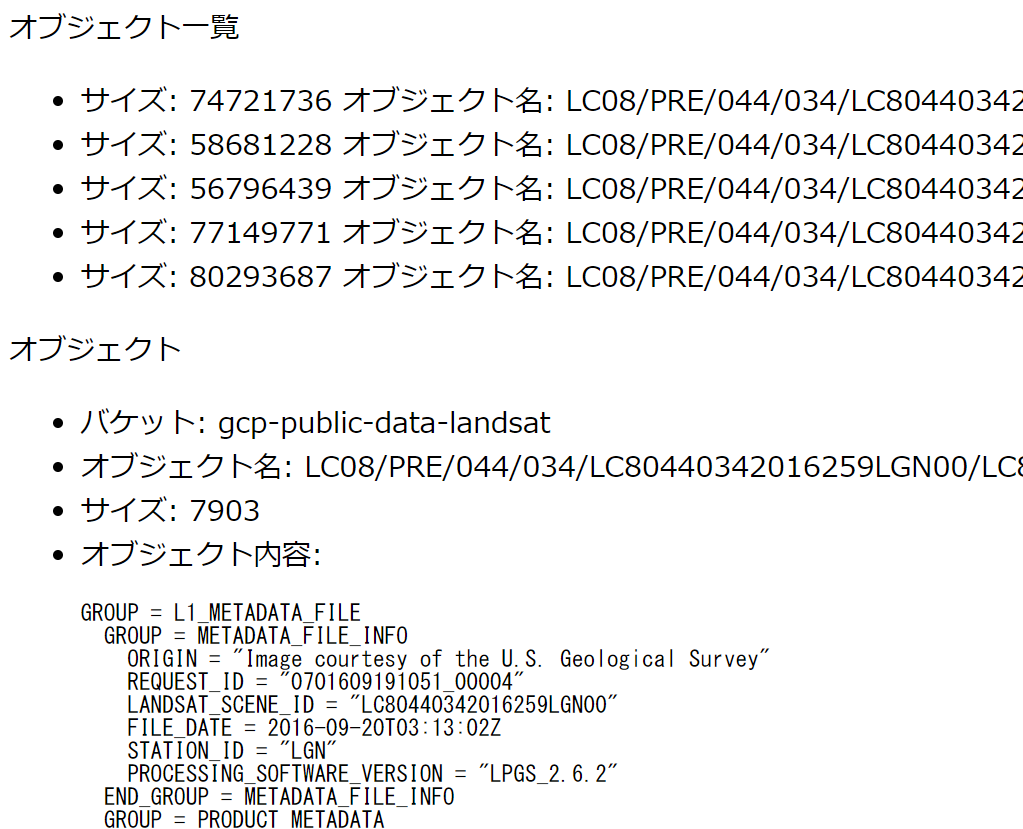
ポイントは以下のとおり。
- google.cloud.storageライブラリを使います。
- storage_client = storage.Client() で、クライアント用のインスタンスを生成します。
- bucket = storage_client.get_bucket(‘gcp-public-data-landsat’) で、バケット gcp-public-data-landsat の情報を取得します。
- blob_list = bucket.list_blobs(prefix=’LC08/(略)N00′, max_results=5) で、バケットの下にあるオブジェクト一覧を取得します。list_blobs() だけだと、バケットの下にある全オブジェクトを取得しようとするので、prefix を使って「この文字列から始まるオブジェクトのみ取得」としています。また、max_results=5 で、5件のみ取得します (画面表示が長くなるのを避けただけです)。
- blob = bucket.get_blob(‘LC08/(略)00/LC(略)MTL.txt’) で、特定のオブジェクトを取得します。
- content = blob.download_as_string().decode(encoding=’ASCII’) で、blob オブジェクトを文字列として取得します。download_as_string() は bytes を返すので、decode で文字列 (str) に変換しています。
Pub/Sub と連携してみよう
Cloud Pub/Sub は GCP のメッセージングサービスです。
メッセージングサービスとは何かについては、Pub/Sub とは何かクラウド メッセージング/キュー比較解説まとめ を参照してください。
コマンドラインから
Pub/Sub を使ったことがない方もいらっしゃるでしょうから、まずは gcloud コマンドでやってみましょう。
まずトピックを作成し、そこにつなげる形でサブスクリプションを作成します。トピックやサブスクリプションとはなんぞや、については、Google 公式の図がわかりやすいと思います。

ではトピックとサブスクリプションを作りましょう。
# トピックを作成
gcloud pubsub topics create mytopic
# サブスクリプションを作成
gcloud beta pubsub subscriptions create mysub \
--topic mytopic --expiration-period=neverこれで、「トピック mytopic → サブスクリプション mysub」というつながりができました。
サブスクリプションは使わないと30日で勝手に消えるという恐ろしい仕様があるのですが、最近 –expiration-period=never というオプションで削除を無効化 (自動削除しない) とすることができるようになったので、ここではそれを指定しています。ただしまだ beta なので、gcloud beta pubsub としています (そのうち gcloud pubsub にも追加されるでしょう)。
「トピック mytopic → サブスクリプション mysub」というつながりができたので、トピック mytopic に対してメッセージを「パブリッシュ」します。するとサブスクリプション mysub にメッセージが伝わり、サブスクリプション mysub から「プル」できます。
下記が「パブリッシュ」するコマンドです。パブリッシュすると、messageId が返ってきます。
% gcloud pubsub topics publish mytopic --message='HOGE'
messageIds:
- '497965854328989'mytopic にパブリッシュしたので、サブスクリプション mysub から pull してみましょう。
% gcloud pubsub subscriptions pull mysub --format=json
表示が崩れてみづらいですが、パブリッシュ時のメッセージID で、”HOGE” という値が入っていることがわかります。
pull したら終わりかと言うとそうではありません。一度 pull したあとに、10秒以上待ってからもう一度同じように pull を発行してください。
% gcloud pubsub subscriptions pull mysub --format=jsonすると全く同じメッセージを取得できてしまいます。このメッセージはもういらないよ、ということを Pub/Sub に伝えるには “ack” (acknowledge) という処理が必要です。
pull した際に ACK_ID という長い長い文字列の表示がありましたが、その ACK_ID を使って下記のように ack します。
gcloud pubsub subscriptions ack mysub --ack-ids=Xk(略)QQ
Acked the messages with the following ackIds: [Xk(略)QQ]
{}なぜこんなめんどくさい仕組みかと言うと、下記のような考え方であるためです。
- pull しただけでは、本当にメッセージを処理できたかわからない。
- pull するからには、そのあとに何かしらの処理、例えば DB に格納したり、ファイルを生成したり、などの処理をしたいのであろう。
- もしかしたら DB 格納やファイル生成時にエラーでプログラムが終了してしまうかもしれないし、マシンがいきなり停止してしまうかもしれない。
- よって、pull したあとに「処理は終了したから Pub/Sub から消していいよ」という指示があるまでは、Pub/Sub 内にメッセージを持っておいて、次回 pull 時に同じメッセージを受け取れるようにしよう。
要はデータを失わないための工夫なわけですね。
コマンドラインから動作確認したい場合は面倒なので、下記のように –auto-ack オプションをつけると、pull と同時に勝手に ack してくれます。
% gcloud pubsub subscriptions pull mysub --auto-ack
publish 画面
まずは publish する画面を作ります。メッセージの内容は 「current time is YYYY/MM/DD HH:MM:SS」と、現在日時を埋めるようにしましょう。
なお、Cloud Shell 上では google-cloud-pubsub モジュールがインストールされていないため、もし ./main.py でローカル実行する場合は事前に下記でインストールしておいてください。
sudo pip3 install google-cloud-pubsubソースコードは下記です。
@app.route('/pubsub_publish')
def do_pubsub_publish():
from flask import render_template_string
from google.cloud import pubsub_v1
import os
topic_name='mytopic'
project_id=os.environ.get('GOOGLE_CLOUD_PROJECT')
topic_path = 'projects/{project_id}/topics/{topic_name}'.format(
project_id=project_id,
topic_name=topic_name,
)
publisher = pubsub_v1.PublisherClient()
from datetime import datetime
message = "current time is {}".format(datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
future = publisher.publish(topic_path, message.encode('utf-8'), attr1='abc', att2='def')
message_id = future.result()
return render_template_string("""(略)""")実行結果 (ブラウザ画面) は下記です。画面を表示しただけで、即 publish し、結果 (message_id) を表示します。

ポイントは下記です。
- google.cloud.pubsub_v1 ライブラリを使います。どうして v1 と付いているんでしょうね?
- “projects/{project_id}/topics/{topic_name}” という文字列を作ります。project_id は環境変数 GOOGLE_CLOUD_PROJECT から取得します。トピック名は mytopic 固定です。
- publisher = pubsub_v1.PublisherClient() で、クライアント用のインスタンスを生成します。
- future = publisher.publish(topic_path, message.encode(‘utf-8′), attr1=’abc’, attr2=’def’) でパブリッシュします。
- topic_path は先程作った “projects/{project_id}/topics/{topic_name}” です。
- メッセージは bytes で送らないといけないので、encode(‘utf-8’) で str から bytes に変換しています。
- publish の際、属性を付与できるので attr1, attr2 をなんとなく付けてみました。属性はなくてもよいです。
- future.result() で message_id を取得できます。
- これで publish 完了です。
pull & ack 画面
pull & ack 画面は下記です。そもそも Web アプリケーションで pull & ack するケースがあるんだろうか? と思わなくもないですが、一応やってみました。
@app.route('/pubsub_pull')
def do_pubsub_pull():
from flask import render_template_string
from google.cloud import pubsub_v1
import os
topic_name='mytopic'
sub_name='mysub'
project_id=os.environ.get('GOOGLE_CLOUD_PROJECT')
sub_path = 'projects/{project_id}/subscriptions/{subscription}'.format(
project_id=project_id,
subscription=sub_name
)
subscriber = pubsub_v1.SubscriberClient()
response = subscriber.pull(sub_path, max_messages=1, return_immediately=True)
if len(response.received_messages) == 0:
return "No messages"
msg = response.received_messages[0]
# ここで何らかの処理をする (DB に格納する、ファイルを生成するなど)
subscriber.acknowledge(sub_path, [msg.ack_id])
return render_template_string((略))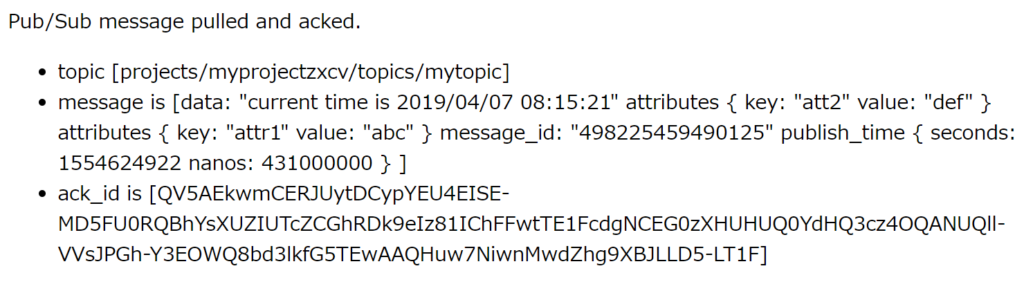
ポイントは下記です。
- google.cloud.pubsub_v1 ライブラリを使います。
- “projects/{project_id}/subscriptions/{subscription_name}” という文字列を作ります。サブスクリプション名は mysub 固定です。
- subscriber = pubsub_v1.SubscriberClient() で、クライアント用のインスタンスを生成します。
- response = subscriber.pull(sub_path, max_messages=1, return_immediately=True) で pull します。
- sub_path は先程作った “projects/{project_id}/subscriptions/{subscription_name}” です。
- max_message を 1 としていますので、最大でも 1つのメッセージしか返ってきません。
- return_immediately=True なので、そのときに pull できるメッセージがなかったらすぐに戻ってきます。これを指定しない場合、pull できるまでずっと待ちます。
- 「何かしらの処理」が終わったら、subscriber.acknowledge(sub_path, [msg.ack_id]) で、取得したメッセージの Ack Id を指定して ack します。
- 何かしらの処理が失敗したら、通常は ack してはいけません。リトライしたら成功するかもしれないので、ack せずに次回 pull されるのを待ちます。
- とはいえ、次回も絶対に失敗することがわかっている場合、例えばメッセージ内のフォーマットが不正などといった場合は次回失敗することが確実なので ack してエラーログに残すケースもあります。
- これで Pub/Sub から該当のメッセージが完全に消えたことになります。
上記はシンプルに書きましたが、大量のメッセージを扱う場合は下記のように工夫してください。
- publish は複数メッセージまとめて行う
- pull も max_messages=1000 として取れる限り一度で取る
- return_immediately=True せず、データが来るまで待ち続ける
また、デフォルトでは 10秒で再度 pull 可能になってしまいますが、サブスクリプションの設定で最大 600秒とすることが可能です。また、pull したメッセージの処理に時間がかかる場合、modify ack deadline で延長する手もあります。
Cloud Memorystore for Redis と連携…はできない
GCP は、Cloud Memorystore というRedis サービスを 2018年9月にリリースしました。しかしながら GAE Standard 2nd gen から、Cloud Memorystore for Redis に接続することはできません。
ではどうするかというと、Google は下記にて Redis Labs という会社が運営する Redis Labs Cloud という PaaS サービスを利用することを勧めています。
https://cloud.google.com/appengine/docs/standard/python3/using-redislabs-redis
どうして Memorystore が使えないんでしょうね。Memorystore は同一リージョン内からしか繋げないという制限に関係するのでしょうか。あるいは MongoDB や Redis の「クラウドサービスはオープンソースにタダ乗りしている!」という批判によるものでしょうか。よくわかりません。
このサービスは AWS・Azure・GCP それぞれのデータセンタ内もしくはデータセンタの近くにサーバを置き、低レイテンシを実現しているのではないかと思います (推測)
Redis Labs の価格表によると、下記のようです。
- 容量 30MB なら無料。同時コネクション30、データベース数は1。
- 容量100MBなら、$5 (キャッシュのみ)、$7 (レプリケーションあり)、$9 (Multi-AZ あり)
- さらに 250MB・500MB・1GB… といったプランあり。
- 東京 (ap-northeast-1) でも利用可能だが、Multi-AZ 未提供、価格が少し高めといった差異がある模様。
GCP と Redis Labs Cloud が連携しているわけではないので、契約・請求・アカウント的にも、全く別です。また、GCP から Redis Labs Cloud へのアウトバウンド通信は普通に課金されるのではないかと思っています (課金されないという記述は見つけられなかった)。
Cloud IAP (Identity-Aware Proxy) で認証を行う
Cloud IAP とは
Cloud IAP (Identity-Aware Proxy )とは、Google が提供する Proxy サービスで、Google アカウントを用いて GAE に認証をかけることができます。
仕組みとしては下図のように、一般利用者と GAE アプリケーションの間に Cloud IAP が位置します。閲覧権限を持つ Google アカウントを持っているユーザならそのまま通し、権限のないアカウントなら認証エラーとします。もし Google アカウントにログイン中でないなら、ログインフォームを表示し、ログインを促します。
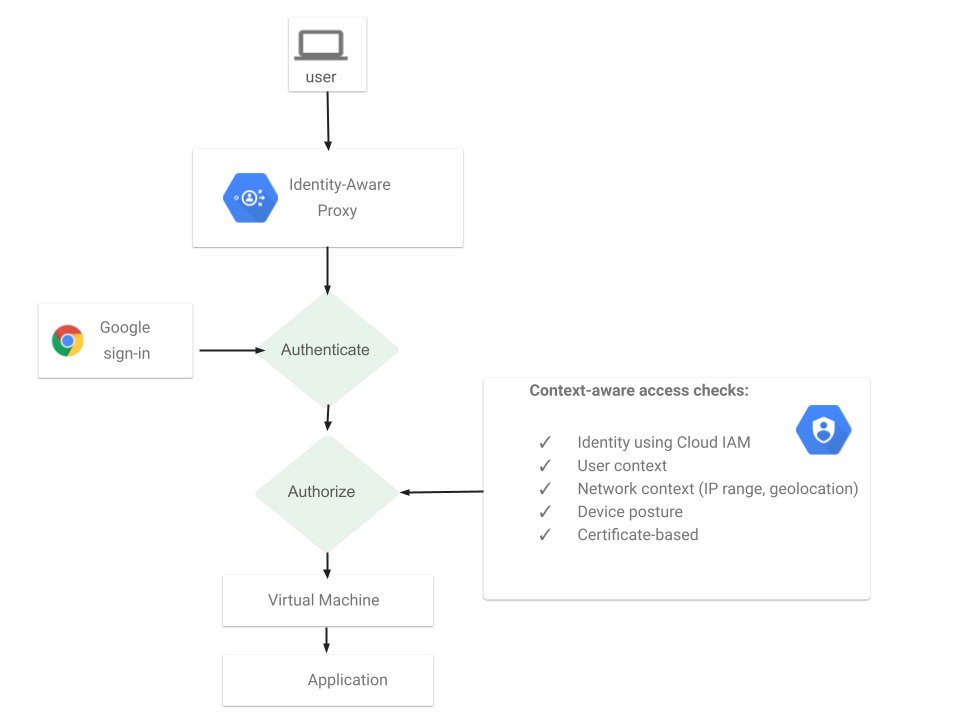
認証OKとする Google アカウントは指定可能なので、あらかじめ指定した人しか GAE にアクセスできなくなります。Google アカウントや Google グループ 単位で指定可能です。
よって、運用上は下記のようになります。
- 新たに閲覧可としたい人がいたら、その人の Google アカウントを Cloud IAP の対象に追加する。
- Cloud IAP に Google グループ単位で閲覧可としておき、新たに閲覧可としたい人がいたら、その人の Google アカウントを Google グループに追加する。
Cloud IAP の制限事項
制限事項は、残念ながらたくさんあります。
- Cloud IAP を有効にできるのは、GAE アプリケーション単位のみ。
- GAE サービス単位での設定はできない。フロント用サービスは一般公開、管理画面用サービスは Cloud IAP で制限、ということはできない。
- GAE バージョン単位での設定もできない。最新バージョンは一般公開、旧バージョンは関係者のみということはできにあ。
- GAE サービス内で、http://xxxxxx/admin/ 以下のみ Cloud IAP 有効ということもできない。
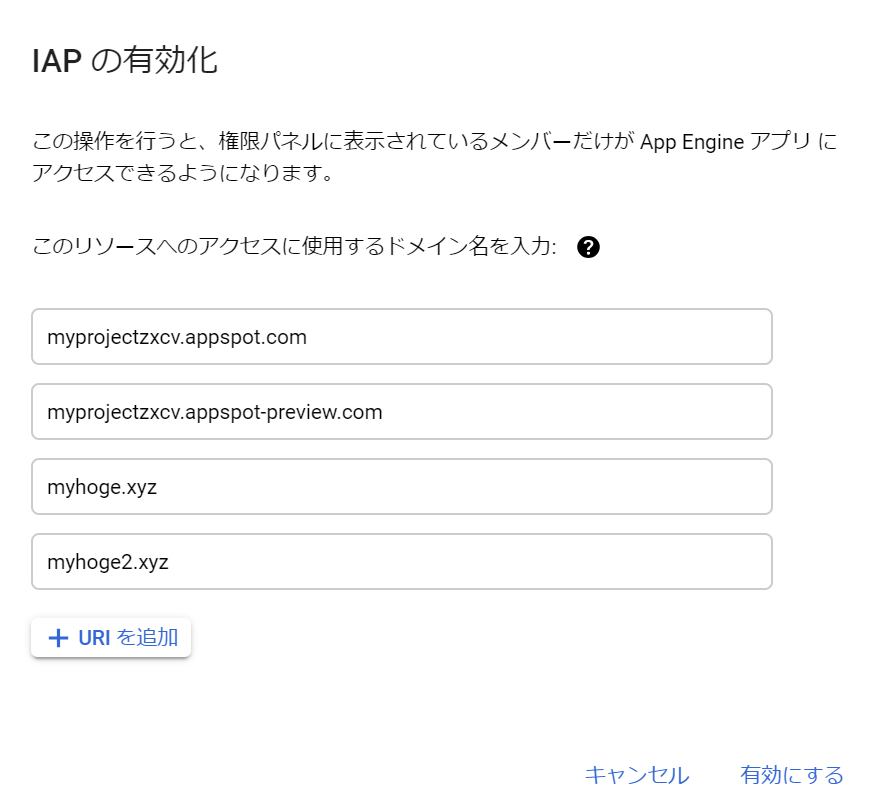
- Cloud IAP 対象のドメインは選択できる。選択したドメインは Cloud IAP 対象となって認証が必要となるが、選択しなかったドメインは一切閲覧できなくなる。
- 例えば同一サービスでカスタムドメインとして aaa.example.com と bbb.example.com を設定し、さらにデフォルトの myproject.appspot.com の合計 3ドメインでアクセス可能な GAE サービスがあったとして、aaa.example.com のみ Cloud IAP 対象とした場合、bbb.example.com や myproject.appspot.com でのアクセスは一切できなくなる (Error: redirect_uri_mismatch というエラーになる)
- http://20190407t194956-dot-myproject.appspot.com のように、バージョン名を GAE まかせにしている場合は手間が増える。デプロイ時に 20190407t194956-dot-myproject.appspot.com というドメインが増えることになるが、Cloud IAP の対象ドメインには含まれていないのでアクセスすることはできない。新しいドメインを Cloud IAP 対象ドメインに追加することは可能だが、手作業でやると大変。
- Google アカウントを持っていさえすれば誰でも OK、という権限付与はできない。
結局のところ、GAE アプリケーション内には管理画面しかなく、固定的な関係者のみが閲覧できるというページに向いているようです、というか、それしかできない、サービスです。
Cloud IAP を使ってみよう
それでもいいよ、という方はやってみましょう。
GAE 管理画面の左メニュー一番下に「設定」がありますのでクリックします。
画面右側に、下記のような「設定」画面が表示されます。初期状態は「アプリケーションの設定」タブが有効になってるはずです。

「アプリケーションの設定」タブの一番下にスクロールすると、「Identify-Aware Proxy」という箇所があるので、「設定する」を押してください。
すると下記のような画面に遷移します。
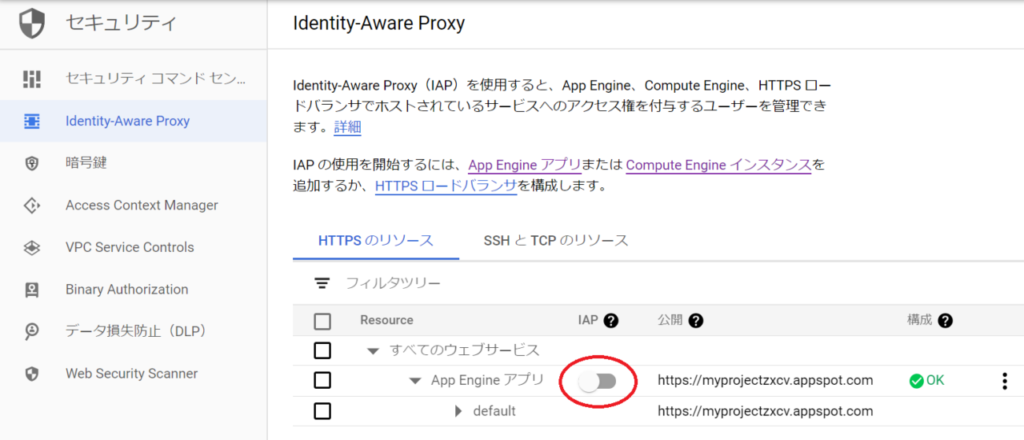
上記画面の赤丸のスライドボタンをクリックすると、下記のダイアログが表示されます。
ライブラリドキュメント
- BigQuery トップ
- Clientクラス
- Client.queryメソッド
- QueryJobクラス (Client.query が返す)
- QueryJob.resultメソッド (SELECT の結果を取得する)
どのライブラリを使えばいいのか
参考:https://qiita.com/gimite/items/652afea6d6bf383ef05a
サービスアカウント
GAE アプリケーションは、デフォルトは App Engine Default サービスアカウントというなので、かなり何でもできる権限があって…
サービスアカウントとは …
ロールとは…
サービスアカウントを設定する
App Engine のサービスは、デフォルトでは App Engine Default サービスアカウントというアカウントで動作します。これは最初から用意されているもので、ほぼ何でもできる権限を持っていると考えてよいでしょう。
お試しで使う分にはそれでいいのですが、個人情報を扱うような本格的なシステムを App Engine に構築する場合は不安があります。
サービスアカウントとは …
ロールとは…
パーミッションとは…
この辺でいけるはず (要確認)
https://github.com/GoogleCloudPlatform/python-docs-samples/blob/master/auth/api-client/snippets.py#L36